�R�D���ʕ���
�@�Q�Q�ȏ�̕�W�c���璊�o�����W�{�f�[�^�āA���܂ǂ̕�W�c�ɑ����邩�s���̃T���@�@�v���f�[�^������Ƃ���B���̃T���v���f�[�^���ǂ̕�W�c�ɑ����邩���ׂ���@�ɁA���ʕ��͂�����B���ʕ��͂����{����ɂ́A�W�߂��W�{���ǂ̕�W�c�ɑ����Ă���̂������炩���ߋ敪�����Ă����K�v������B�敪��������@�ɁA���`���ʎ����g�p������@�ƁA�}�n���m�r�X�̋�����p������@������B
�R�D�P�@���`���ʎ����g�p������@
�@���ϗʃf�[�^��1���2�c��n ������Ƃ���B���̐����ϗʂ�1���2�c��n �͂�������ʓI�f�[�^�ł���A���̕ϗʂɓK���ȏd�݂�1���2�c��n �����ړI�ϗʂy��B
�y����1���1�{��2���2�{�c�{��n���n�{��0
���̎�������ړI�ϗʂy���敪�킯���������I�f�[�^�ł���Ƃ��A���̎�����`���ʎ��Ƃ����B�d��A���ł́A�����ϗʂ��ړI�ϗʂ��ʓI�f�[�^�����������A���ʕ��͂ɂ����ẮA�����ϗʂ͗ʓI�f�[�^�ł��邪�A������ړI�ϗʂ͂ǂ̕�W�c�ɑ�����̂��������I�f�[�^�������B
�@���܁A�`���w�Z�̂W�l�̐��k�̉p��i��1�j�Ɛ��w�i��2�j�̕]��������A���̂W�l�̐��k���a���Z�����Ă��̍��ی��ʁi�y�j���������Ă���Ƃ���B����ƁA�����ɂQ�̕�W�c�A���i�Q�ƕs���i�Q�����邱�ƂɂȂ�B
|
NO |
�����ϗ� �p��(��1)�@�@���w(��2) |
�ړI�ϗʁi�y�j ���@�� |
|
�P �Q �R �S �T �U �V �W |
�T�@�@�@ �W �T �@�@�@�T �V �S �W �T �V �Q �S �R �W �V �S �U |
�� �� �� �� �� �� �� �� |
|
���� |
�U �T |
|
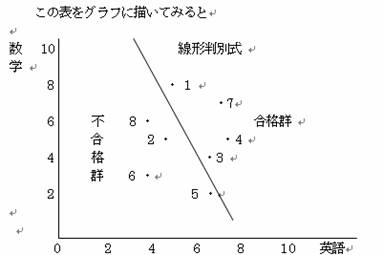
���i�����Q�i�P��R��S��V�j�ƕs���i�̌Q�i�Q��T��U��W�j���敪�킯���钼�����P�{�l����B
���̒������A���`���ʎ��ƂȂ�B���̐��`���ʎ�����������A�ǂ̕�W�c�ɕt������̂��s���̃T���v���f�[�^�̏����邱�Ƃ��ł���B
3.1.1�@���`���ʎ������߂�B
�@�����ϗʂ��Q����̂ł������1�E��2 �Ƃ���ƁA���̔��ʎ���
�@�@�@�@�y����1���1�{��2���2�{��0 �Ƃ���B
�@���i�����Q���`�Q�A�s���i�̌Q���a�Q�Ƃ���ƁA���̔��ʎ��y�́A�Q�Q�i�`�Q�Ƃa�Q�j����ł������ʒu�Ɉ������K�v������B�Q�Q����ł������ʒu�Ɉ�����邱�Ƃɂ��A���̔��ʎ��́A�Q�Q�`�E�a���敪������ł��ǂ�����ƂȂ�B

�i�P�j���ʓ��_�����߂�
�@�@�@���ʓ��_�́A�e�W�{�f�[�^�_���画�ʎ��܂ł̋����ŕ\�����B
�@�@�@���Ƃ̕W�{�����i�����Q�ƕs���i�̌Q�ɕ����Đ��������
|
NO |
�����ϗ� �p��(��1) ���w(��2) |
�ړI�ϗʁi�y�j ���@�� |
|
|
�P �R �S �V |
�T
�W �V
�S �W
�T �W
�V |
�� �� �� �� |
A �Q |
|
�� �� |
�V
�U |
|
|
|
�Q �T �U �W |
�T
�T �V
�Q �S
�R �S
�U |
�� �� �� �� |
B �Q |
|
�� �� |
�T
�S |
|
|
|
�S���� |
�U
�T |
|
|
�����ϗʂ�1���2�͗ʓI�f�[�^�ł���A�ړI�ϗʂy�͋敪���������I�f�[�^�ł���B
�ʏ�ʓI�f�[�^�Ԃ̊W��\�����̂Ƃ��Ă͑��W�������邪�A�ʓI�f�[�^�Ǝ��I�f�[�^�́@�@�W��\�����̂Ƃ��đ��֔�i�Łj������B���֔�i�Łj��
��2�����ԕϓ����S�ϓ�
�ŗ^������B



����1.381,�|1�@�ő��֔��2�͍ő�l�܂��͍ŏ��l�����B���̂��̒l�𑊊֔��2�ɑ������Ƃ����|1�̎� ��2���O�@�ƂȂ�ŏ��ƂȂ�B����1.381�̎� ��2��0.71556�@�ƂȂ�ő�ƂȂ�B�܂葊�֔��2�́A��1����2���|1�̎��ŏ��ƂȂ�A��1����2��1.381�̎��ő�ƂȂ�B���܋��߂悤�Ƃ��Ă���̂́A���֔��2���ő�Ƃ��邁1���2�ł��邩��A1.381���̗p����B
���ʎ��́A�y����1���1�{��2���2�{��0 �ł��邩�炱���ό`����
�@�@�@Z = x1�{ x2 �{ ��1.381�ł��邩��A�y��1.381��1�{��2�{
�@�@�萔���� ���܂��s���ł���
 �� 10
���`���ʎ�
�� 10
���`���ʎ�
�w
8
�E
�E ���i���-�߂̒��S(7,6)
6
�E �B
�E �E
4
�B �E
�E
�s���i��ٰ�߂̒��S(5,4)
2
�E
�@
0
2
4
6
8
10 �p��

�����苁�߂���`���ʎ��́A�y��1.381��1�{��2�|13.286 �ƂȂ�B���̐��`���ʎ����g�p���邱�Ƃɂ��A�f�[�^���Q�Q�ɕ����邱�Ƃ��ł���B
���ۂɔ��ʓ��_�����߂ĕ\�ɂ��Ă݂��
|
NO |
��1 �p�@�� |
��2 ���@�w |
���ʓ��_ |
�Q |
|
�P �R �S �V |
�T �V �W �W |
�W �S �T �V |
1.619 0.381 2.762
4.762 |
�� �i |
|
���� |
�V |
�U |
2.381 |
|
|
�Q �T �U �W |
�T �V �S �S |
�T �Q �R �U |
�|1.381 �|1.619 �|4.762 �|1.762 |
�s �� �i |
|
���� |
�T |
�S |
�|2.381 |
|
|
�S���� |
�U |
�T |
0 |
|
���ʓ��_������ƁA���i�Q�́{�@�s���i�Q�́|�ɌQ��������Ă��邱�Ƃ�������B
�@�@�@�ȏォ��A�O���t��`���Ă݂��
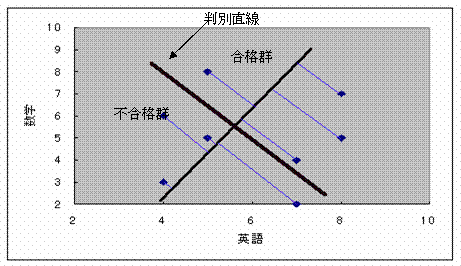
�@���ʒ��������ɂ��āA�E���ɍ��i�Q�A�����ɕs���i�Q�����邱�Ƃ�������B
�܂��S���ρi�U�A�T�j��ʂ蔻�ʒ����ɒ��s���钼�����P�{�����A���̒�����Ɋe�_����~�낵���_������ƁA�S���ρi�U�A�T�j��V���Ȍ��_�ƍl����Ə㑤�i�{���j�ɍ��i�Q�A�����i�|���j�ɕs���i�Q�����肻�̋��������ʓ��_�ƂȂ��Ă��邱�Ƃ�������B
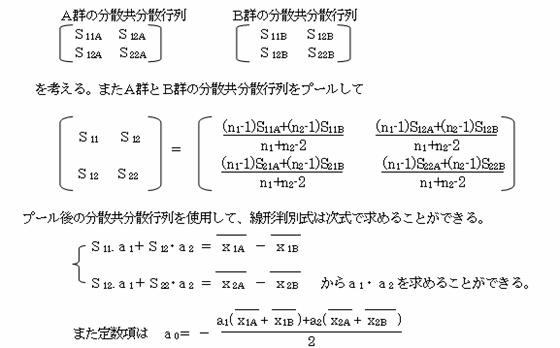
3.1.2�@���U�E�����U�s���p���Ĕ��ʎ������߂�B�i�s�Ε��U���g�p����j
�i�P�j�����ϐ����Q�̎�
���ʎ�
�y����1���1�{��2���2�{��0 �����߂�̂ɕ��U�����U�s��𗘗p���ċ��߂�� �@������B���ܐ����ϗʂ���1���2�ƂQ����A�`�Q��a�Q�̂Q�Q�ɕ�����Ă���B
|
�Q |
�W�{NO |
��1 |
��2 |
|
�` �Q |
�P �Q �c ��1 |
��11A ��12A �c ��1�n1A |
��21A ��22A �c ��2�n1A |
|
���� ���U |
�r11A |
�r22A |
|
|
�����U |
�r12A |
||
|
�a �Q |
�P �Q �c ��2 |
��11B ��12B �c ��1�n2B |
��21B ��22B �c ��2�n2B |
|
���� ���U |
�r11B |
�r22B |
|
|
�����U |
�r12B |
||
���܂`�Q�E�a�Q����̗l�ɂȂ��Ă���Ƃ�
�@
�i�Q�j�����ϗʂ������鎞�ɂQ�`�Q�E�a�ɕ�����Ƃ�
|
�Q |
�W�{NO |
��1
��2
�c
��p |
|
�` �Q |
�P �Q �c ��1 |
��11A ��21A �c ��p1A ��12A ��22A �c ��p2A �@�@�@�@�c ��1�n1A ��2�n1A �c ��p�n1A |
|
|
���� |
�c
|
|
�a �Q |
�P �Q �c ��2 |
��11B ��21B �@�c ��p1B ��12B ��22B �c ��p2B �@�@�@�@�c ��1�n2B ��2�n2B �c ��p�n2B |
|
|
���� |
�c |
���̎��A�`�Q�̕��U�����U�s����rA�A�a�Q�̕��U�����U�s����rB�@
�@�@�v�[����̕��U�����U�s����r�Ƃ����

�R�D�Q�@�{�b�N�X�l����
�@���`���ʎ����g�p���ĂQ�Q���敪�킯�ł���̂́A�ꕪ�U�����U�s���������Ɍ����@�@��B�Q�Q�̕ꕪ�U�����������ɂ́A���̔��ʎ��͒����ɂȂ邪�A�������Ȃ����ɂ͔��ʎ��͋Ȑ��ƂȂ�B�ꕪ�U�����U�s�������Ȃ����ɂ́A�}�n���m�r�X�̋����ɂ�锻�ʂ��s���K�v������B�ꕪ�U�����U�s���������ǂ����̌���Ɂu�{�b�N�X�l����v������B
�u�{�b�N�X�l����v
�`�Q�E�a�Q�̂��ꂼ��̕��U�����U�s����rA�E�rB�Ƃ���B�܂��rA�E�rB�̃v�[����̕��U�@�@�����U�s����r�Ƃ����

p�F�����ϗʂ̌��@��A�F�`�Q�̕W�{�� ��B�F�a�Q�̕W�{��
���R�x�@���i���{�P�j�^�Q�̃�2 ���z�ɑQ�ߓI�ɏ]���B����𗘗p���Č�����s���B
(1)����������
�@ �A�������@�g0 �F�Q�Q�̕ꕪ�U�����U�s��͓�����
�@ �Η������@�g1 �F�Q�Q�̕ꕪ�U�����U�s��͓������Ȃ�
(2)���蓝�v�ʃ�2�͎��R�x���i���{�P�j�^�Q�̃�2 ���z�ɏ]���B
(3)�L�א��������Ƃ����
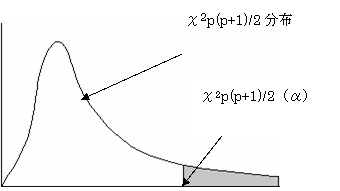
�@�@�@
��2 ��
��2p(p+1)/2�i���j�ł���Ή��������p����B�܂�A�Q�Q�̕ꕪ�U�����U�s��͓������Ȃ��B����ă}�n���m�r�X�̋����ɂ�锻�ʏ�������������]�܂����B
�R�D�R�@�}�n���m�r�X�̋����ɂ�锻��
3.3.1�@�}�n���m�r�X�̋���
�i�P�j�P�ϗʎ��̃}�n���m�r�X�̋���

�P�ϗʂ̃f�[�^�`�Q�Ƃa�Q����̗l�ɕ��z���Ă���Ƃ���B�`�Q�̃f�[�^�͕��U�̑傫���f�@�@�[�^�Q�A�a�Q�̃f�[�^�͕��U�̏������f�[�^�Q�ł���B���̎������s���̃f�[�^��p�����鎞�A���̏����s���̃f�[�^��p���`�Q�A�a�Q�̂ǂ���ɏ�������f�[�^�ł��邩���ׂ�
�@�P���ɂ�p���炻�ꂼ��̌Q�̒��S�܂ł̋���������ƁA���炩�ɂ��̂�p�͂a�Q�̒��S�Ɂ@�@�߂��B![]() �ƂȂ��Ă��̂ŁA���̂�p�͂a�Q�̃f�[�^�ł���悤�Ɏv����B�������`�Q�͕��U�̑傫���f�[�^�Q�ł���A�a�Q�͕��U�̏������f�[�^�Q�ł���B���̕��U���l�����Ȃ��ŁA�P���ɋ��������łǂ���̌Q�ɏ�������̂��f���邱�Ƃ͂ł��Ȃ��B���̕��U���l�����������Ɂu�}�n���m�r�X�̋����v������B
�ƂȂ��Ă��̂ŁA���̂�p�͂a�Q�̃f�[�^�ł���悤�Ɏv����B�������`�Q�͕��U�̑傫���f�[�^�Q�ł���A�a�Q�͕��U�̏������f�[�^�Q�ł���B���̕��U���l�����Ȃ��ŁA�P���ɋ��������łǂ���̌Q�ɏ�������̂��f���邱�Ƃ͂ł��Ȃ��B���̕��U���l�����������Ɂu�}�n���m�r�X�̋����v������B
�P�ϗʎ��̃}�n���m�r�X�̋������c2�Ƃ���ƁA
 �i
�i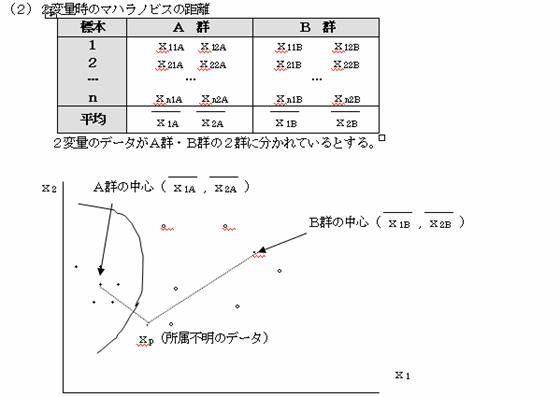
�`�Q�͕��U�̏������f�[�^�Q�A�a�Q�͕��U�̑傫���f�[�^�Q�Ƃ���B���̎������s���̃f�[�^��p�i��1,��2�j�����鎞�A���̃f�[�^��p�͂`�Q�E�a�Q�̂ǂ���ɏ�������f�[�^�ł��邩���ׂ�B

�@�@�@�@�@�@�@�@�@�@�@�@

�R�D�S�@���ϗʂɂ�����Q�Q�̕ꕽ�ς̍��Ɋւ��錟��
3.4.1�@�Q�Q�Ԃ̕ꕽ�ςɍ������邩�ǂ���������s���B
���܂Q�Q�����ꂼ��m�i��1�C��2�j�E�m�i��2�C��2�j�ɏ]���Ƃ��A�������炎1�E��2�̕W�{���Ƃ���B���̎��Q�Q�̕ꕽ�σ�1����2�ł��邩�ǂ��������
�@���蓝�v�ʂ��e�Ƃ����
�@�@�@![]()
���������F�����ϗʂ̌��@�c2�F�Q�Q�̒��S�Ԃ̃}�n���m�r�X�̔ċ���
�@�͎��R�x���C��1�{��2�|���|�P�̂e���z�ɏ]���B����𗘗p���Ă��ϗʂ̂Q�Q�̕ꕽ�ς́@�@�@���̌�����s��
(1)����������
�@ �A������
�g0�F��1����2 �i�Q�Q�̕ꕽ�ς͓������j
�@ ������
�g1�F��1����2 �i�Q�Q�̕ꕽ�ς͓������Ȃ��j
(2)���蓝�v�ʂe�͎��R�x���C��1�{��2�|���|�P�̂e���z�ɏ]��
(3)�L�א������Ō���������Ȃ�
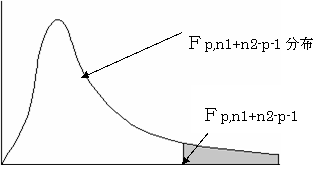
�e���ep,n1�{n2�|p�|1�i���j�ł���Ή����g0�����p����B�܂�Q�Q�̕ꕽ�ςɍ�������@�@�@�@�Ƃ���B
3.4.2�@�E�B���N�X�̃��i�����_�j���v��
���ϗʎ��̌Q�Ԃ̕ϓ��������ʂƂ��āA�E�B���N�X�̃����v�ʂ�����B
�@�@ �Q�Q�̑��ϗʃf�[�^�����̕\�̂悤�ɂ���Ƃ����
|
�Q |
�ϗ� �W�{ |
�w1 �@ �w2 �@ �c�@�@�wp |
|
�` �Q |
�P �Q �c ��1 |
�w11A �w21A �c�@ �wp1A �w12A �w22A �c�@ �wp2A �c �w1�n1A
�w2�n1A �c�@ �wp�n1A |
|
�a �Q |
�P �Q �c ��2 |
�w11B �w21B �c�@ �wp1B �w12B �w22B �c�@ �wp2B �c �w1�n2B
�w2�n2B �c �wp�n2B |
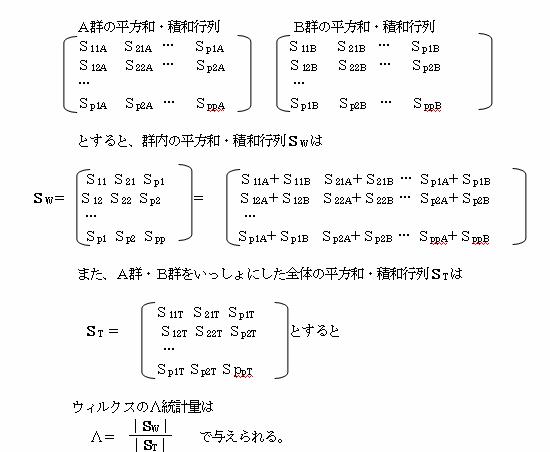 �����v�ʂ́A�O�������P�̒l���Ƃ�A�����O�ɋ߂��قǂQ�Q�Ԃ̍����傫���A�����P�ɋ߂Â��قǂQ�Q�Ԃ̍����������Ȃ�B
�����v�ʂ́A�O�������P�̒l���Ƃ�A�����O�ɋ߂��قǂQ�Q�Ԃ̍����傫���A�����P�ɋ߂Â��قǂQ�Q�Ԃ̍����������Ȃ�B
���̃����v�ʂ��g�p���āA�Q�Q�Ԃ̕ꕽ�ς̍��̌�������邱�Ƃ��ł���B
�Q�Q���ϗʂ̕ꕽ�ς����ꂼ���iA�E��iB�Ƃ���ƁA��iA����iB�̉��艺��
���蓝�v�ʂ��e�Ƃ���ƁA
�@�@�@�@�@
��L���蓝�v�ʂe���g�p���āA�L�א������ʼn����g0�F��iA����iB i=1,2�cp �����肵�A�����e���ep,n�|p�|1�i���j�ł���Ή��������p���A�Q�Q�̕ꕽ�ςɍ�������Ƃ���B
�R�D�T�@���ʕ��͂̓I����
�@���ʕ��͂����{���ď�������Q�ʂ����Ƃ��A���̕W�{���{���ɏ������Ă����W�c�Ɛ��������肳�ꂽ���ǂ����̐��x���v����̂ɔ��ʓI����������B
���ʓI�������i���������ʂ��ꂽ�W�{���S�W�{�̐��j�~�P�O�O �ł���B
�R�D�U�@�딻�ʂ̊m��
�@��W�c���Q���鎞�A����W�{���Ԉ������W�c����̕W�{�ł���Ɣ��肷����̊m�@�@�@�����딻�ʂ̊m���Ƃ���
�W�{���Q�`�Q�E�a�ɕ�����Ă���A���̐����ϗʂ������鎞�A�`�Q�̐����ϗʂ̕��ς��@�@�@��1A�E��2A�c��pA�A�܂��a�Q�̐����ϗʂ̕��ς���1B�E��2B�c��pB �Ƃ���B���̎��A�`�Q�̒��S����a�Q�ւ̒��S�ւ̃}�n���m�r�X�̋����c02 ��
 ���܂o1���`�Q�̕W�{�ł���ɂ�������炸�A�a�Q�̕W�{�ł���Ɣ��肷��ԈႢ�̊m���B �@�@ �܂��o2���a�Q�̕W�{�ł���ɂ�������炸�A�`�Q�̕W�{�ł���Ɣ��肷��ԈႢ�̊m���Ƃ���ƌ딻�ʂ̊m���́A�o1���o2���W�����K���z��
���܂o1���`�Q�̕W�{�ł���ɂ�������炸�A�a�Q�̕W�{�ł���Ɣ��肷��ԈႢ�̊m���B �@�@ �܂��o2���a�Q�̕W�{�ł���ɂ�������炸�A�`�Q�̕W�{�ł���Ɣ��肷��ԈႢ�̊m���Ƃ���ƌ딻�ʂ̊m���́A�o1���o2���W�����K���z��![]() �j�l�̏㑤�m���ł���B
�j�l�̏㑤�m���ł���B
 �@�@�@�@�@
�@�@�@�@�@�@�@
�@�@�@�@�@
�@�@�@�@�@�@�@
�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@![]()
�R�D�V�@�����ϗʂ̊�^
�@���`���ʎ����A�y����1��1�{��2��2�{�c�{��n��n�{��0�Ƃ���B���̎��W����i���A���ʎ��Ɋ�^���Ă��邩�ǂ������ׂ�B������^���Ă��Ȃ��̂ł���A���̐����ϗʂ͂Ȃ��Ă����ʌ��ʂɉe����^���Ă��Ȃ��̂ŁA���`���ʎ����痎�Ƃ��Ă��悢�W���ł���B
�Q�`�Q�E�a�Ő����ϗʂ������鎞�A���̕\�̂悤�ł���Ƃ���B
|
�Q |
�W�{NO |
��1 �@ ��2 �c ��p |
|
�` �Q |
�P �Q �c ��1 |
��11A
��21A �c ��p1A ��12A
��22A �c ��p2A �c ��1�n1A ��2�n1A �c ��p�n1A |
|
�a �Q |
�P �Q �c ��2 |
��11B
��21B
�@�c ��p1B ��12B
��22B �c ��p2B �c ��1�n2B ��2�n2B �c ��p�n2B |
�c2P�@�F�o�̕ϗʂ��g�p�����Q�Q�̒��S�Ԃ̃}�n���m�r�X�̋����B�c2P-1�F�o�̕ϗʂ��炠�����̕ϗʂ��P���Ƃ����Ƃ��̂Q�Q�̒��S�Ԃ̃}�n���m�r�X�̋��� �Ƃ����
 ������s��
������s��
(1)����������
�@�@�A�������@�g0�F��i���O�@�i�W����i�͖��ɂ����Ȃ��j
������
�g1�F��i���O
(2)���蓝�v�ʂe�͎��R�x�P�C��1�{��2�|���|�P�̂e���z�ɏ]���B
(3)�L�א������Ō�����s��

�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@
�e���e1,n1�{n2�|p�|1(��)�ł���A�����g0�����p����B�܂�W����i�͔��ʎ��Ɋ�^���Ă���Ƃ�����B
���ʎ��Ɋ�^���Ă��Ȃ��W���́A�g�p���Ȃ��Ă����ʂɉe����^���Ă��Ȃ��̂ŕs�K�v�ȕϗʂł���Ƃ�����̂ŁA���̌W���͍폜���Ă��\��Ȃ��B
�@���̌W���̊�^�ɂ��Ă̂e�l���g�p���邱�Ƃɂ��A�d��A���Ɠ��l�ɕϐ��I���̑O�i�I��@�E��ތ����@�Ȃ�тɕϐ������@�Ȃǂ̕ϐ��I�������s���邱�Ƃ��ł���B
�R�D�W�@�悢���ʎ����쐬����B
�@���ʎ��ł́A�������̗ʓI�f�[�^�ł�������ϗʂ���敪�킯���������I�f�[�^�ł���ړI�ϗʂ�B���̎��d��A���Ɠ��l�ɐ����ϗʂ��ނ�݂ɑ������Ă����ʂȂ��Ƃ������B�悢���ʎ��́A���Ȃ������ϗʂŐ��x�̍����敪�킯���ł���悤�Ȏ��ł���B���̂��߂ɐ����ϗʂׁA���ʎ��ɕK�v�ȕϗʂł��邩�ǂ�����������K�v������B
3.8.1�@�����ϗʑI���̊
�i�P�j�ړI�ϗʂɗ^����e���̑傫�������ϗʂ�I�ԁB
�@�d��A���͂ł́A�����ϗʁE�ړI�ϗʂƂ��ɗʓI�f�[�^�ł���̂ŁA���̊W�͑��W���Œ��ׂ邱�Ƃ��ł������A���ʕ��͂ł͐����ϗʂ͗ʓI�f�[�^�ŖړI�ϗʂ͎��I�f�[�^�ł���B���̂悤�ɗʓI�f�[�^�Ǝ��I�f�[�^�Ԃ̊W�ׂ�ɂ͑��֔�i�Łj���g�p����B
�Ȃ��A���֔�i�Łj�́A�O���Ł��P�̒l���Ƃ�A�P�ɋ߂��قNj��ԕϓ����傫���Q�ϗʊԂ̊W�������Ƃ�����B
�@���ܐ����ϗʂ�����������A���̒��̂P�̕ϗʂ����Q�`�Q�E�a�ɕ�����Ă���Ƃ���B���̎��̑��֔�����߂�B
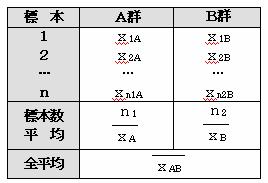

�e�ϗʂɂ��đ��֔�����߁A���֔�̑傫���ϗʂقǖړI�ϗʂɗ^����e�����傫���Ƃ��@�@����̂ŐϋɓI�ɔ��ʎ��ɍ̗p����B
�m���֔�Ɋւ��錟��n
�ϗʂ�1�c��p�����݂��ɓƗ��ł���A�Ƃ��ɐ��K���z�ɏ]�����̂Ƃ���B
(1)����������
�@�@�@ �A������
�g0�F��0���O
�i�ꑊ�֔䁁�O�j
�@�@�@ ������
�g1�F��0���O
�i�ꑊ�֔䁂�O�j
(2)���蓝�v�ʂ��e�Ƃ���
�e��
�͎��R�x���|�P�C���|���̂e���z�ɏ]��
���F�W�{���@���F�ϗʐ�
(3)�L�א������Ō��肷��
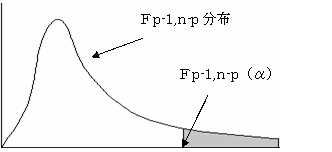
�e���ep�|1,n�|p�i���j�ł���A���������p����B�܂�ꑊ�֔䁂�O�Ƃ���B
�i�Q�j�����ϗʊԂł��݂��ɍ������ւ����鎞�ɂ́A�ǂ��炩�̕ϗʂ𗎂Ƃ��B�����ϗʊԂ̑��ւɂ��ẮA�P���W����p���Ē��ׂ�B����͏d��A���Ɠ��l�ɐ����ϗʊԂł��݂��ɍ������ւ�����Ƃ��ɂ́A���d����������������ł���B���݂��������ւ�����ϗʂ́A�������Ƃ�������Ă���̂ŁA�ǂ��炩����̕ϗʂ𗎂Ƃ��Ă��ړI�ϗʂɗ^����e���͏������A���ʌ��ʂɍ��ق͂Ȃ��Ƃ�����B
���d�������ׂ�ɂ́A�W����i�̕����ƂQ�Q�̕��ς̍��i�|�j�̕������s��v�̂Ƃ��ɑ��d������������̂ł����ɒ��ׂ邱�Ƃ��ł���B
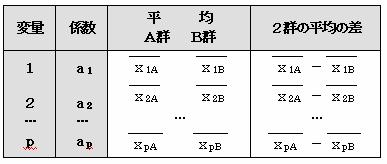
�u�W����i�̕����v�Ɓu�Q�Q�̕��ς̍��̕����v������A���d��������������B
3.8.2�@���ʎ��ɂ�����ϐ��I��@
�@�d��A���̎��Ɠ��l�ɁA���ʎ��ɂ����Ă������ϗʑI���̕��@������B�@�@
�@�����ϗʂ̑I���̕��@�ɂ́A�d��A�����l�u�ϐ������@�v�u�ϐ������@�v�u�ϐ������@�v�u�ϐ������@�v�Ȃǂ�����A�����̕��@���d��A���̎��Ɠ����悤�ɍs���B
�ϗʍ̔ۂ̊�Ƃ��ẮA�����ϗʂ̊�^�ł̌W����i�̂e�l���������Ȃ���s���B
�S�D�@���ʕ��͗��
�@�����Ђ�K�₵�Ă������Ђ̎Ј��i�`�ƊE�Ј��Ƃa�ƊE�Ј��j�ɂ��āA���̈�ۂɂ��āA�P�O�_�]���������̂����̕\�ł���B�`�ƊE�Ј��Ƃa�ƊE�Ј��Ԃň�ۂɈႢ�����邩�ǂ������ׂ�B
|
�m�n |
�w1 ��V |
�w2 �ϋɐ� |
�w3 ������ |
�w4 �ƊE�敪 |
|
�P �Q �R �S �T �U �V �W |
�R �W �U �W �V �S �U �V |
�W �Q �V �U �R �V �R �T |
�S �U �U �S �T �R �U �W |
�` �a �` �` �a �` �a �a |
���e�_�́A�P�O(��)�`�O(��)�@�̂P�O�_�]���l�B�ƊE�敪�͂`�ƊE�Ƃa�ƊE�̂Q��
�@��̕\�����Ƃɂ��āA���ʕ��͂����{���Ă`�ƊE�Ƃa�ƊE�̎Ј��Ԃň�ۂ��Ⴄ���ǂ������@�ׂ�B�`�ƊE���u�P�v�E�a�@�ƊE���u�Q�v�Ǝ��I�敪�f�[�^�ɒu��������B�����f�[�^���玿�I���l�f�[�^�ɒu���������f�[�^���g�p���Ĕ��ʕ��͂����s����B
|
�m�n |
�w1 ��V |
�w2 �ϋɐ� |
�w3 ������ |
�w4 �ƊE�敪 |
|
�P �Q �R �S �T �U �V �W |
�R �W �U �W �V �S �U �V |
�W �Q �V �U �R �V �R �T |
�S �U �U �S �T �R �U �W |
�P �Q �P �P �Q �P �Q �Q |
�@���ʕ��͂����{����ɂ́A�܂����͂���f�[�^����͂��āB�P�P�[�X������̕ϐ��͂w1�`�w4�ł���A�m�n�P�`�m�n�W�@�܂ł̂W�P�[�X���̃f�[�^������B���͗p�f�[�^���͌�A���ʕ��͂����{����B
�S�D�P�@���ʕ��͂̎��{
�@�{�b�N�X�l��������{���A���`���ʎ��ŋ敪���邩�A�}�n���m�r�X�̋�����p���Ĕ��ʂ��邩�����肷��B
�@�{�b�N�X�l����́A�Q�����������̂Q�Q�̕ꕪ�U�����U�����������ǂ����̌���ł���B�@�@�@�{�b�N�X�l����̌��ʂQ�Q�̕ꕪ�U�����U����������A�Q�Q�͐��`���ʎ��ŋ敪���邱�@�@�@�Ƃ��ł���B�Q�Q�̕ꕪ�U�����U���������Ȃ���}�n���m�r�X�̋����ɂ�锻�ʕ��͂����{����B
4.1.1�@�Q1�iA�ƊE�j�E�Q2�iB�ƊE�j���ꂼ��̕��U�E�����U�����߂�


4.1.2 ���蓝�v�ʂ���2 �Ƃ��āA���̌��蓝�v�ʂ����߂�B
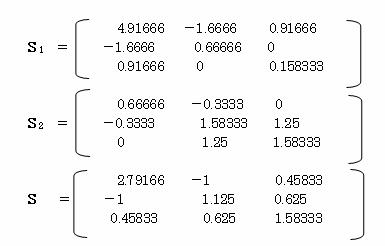
�Q�P�i�`�ƊE�Ј��j�̕��U�����U�s����r1�A�W�{������1�A�Q�Q�i�a�ƊE�Ј��j�̕��U�����U�s����r2�A�W�{������2�A�܂��v�[���������U�����U�s����r�A�ϗʐ������Ƃ����
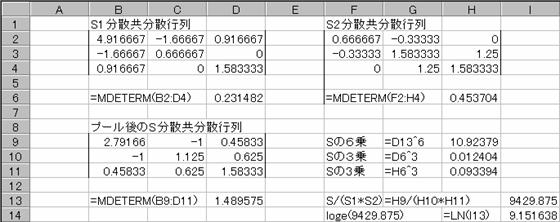
�s�̒l�́A��MDETERM(�͈́j�ŋ��߂�B�����������s��Ɍ���
�ȏ�����g�p���ċ��߂��l�������


4.1.3�@��������{
�A�������F�g0 �F�Q�Q�̕ꕪ�U�����U�͓�����
�Η������F�g1 �F�Q�Q�̕ꕪ�U�����U�͓������Ȃ�
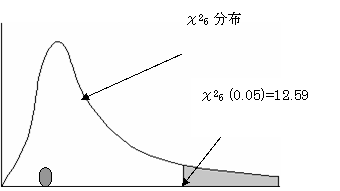
��
��2=4.1945
��2 �� ��26 (0.05) �ł���A���p��ɓ���Ȃ��B����ĉ����g0�F�i�Q�Q�̕ꕪ�U�����U�͓������j�����p�ł��Ȃ��B�Q�Q�̕ꕪ�U�����U�s��͓������Ȃ��Ƃ͂����Ȃ��B����ĂQ�Q���A���v���ʎ��ŕ�����B
�S�D�Q�@���`���ʎ������߂�B
4.2.1�@���U�����U�s������߂�B
�Q�P�E�Q�Q�̕��U�����U�s������ꂼ���r1�E�r2 �A�v�[���������U�����U�s����r��
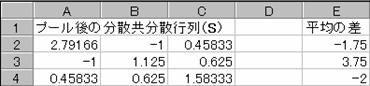
4.2.2�@�Q�P�ƌQ�Q�̊e�ϗʂ̕��ϒl�̍����Ƃ�

�v�[����̕��U�����U�s��S�ƁA���ς̍��̍s�����͂���B
���U�����U�s��̋t�s������߂�B
�@�擪�̒l����MINVERSE(�s��͈�)�ŋ��߂�B

�擪�̒l�����܂�����A��������t�s������߂�͈͂��h���b�O���A���ɐ����o�[���N���b�N������ACTRL�L�[�{SHIFT�L�[�{ENTER�L�[�������āA�z����������B
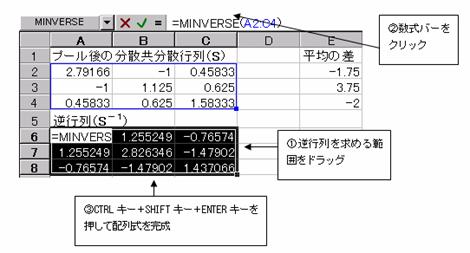
���܂���S�̋t�s��iS-1)�ƕ��ς̍��̍s��̐ς����߂�B
 �擪�̒l����MMULT(�s��1�͈́C�s��2�͈�)�ŋ��߂�B
�擪�̒l����MMULT(�s��1�͈́C�s��2�͈�)�ŋ��߂�B
�s��ς����߂�͈͂��h���b�O������A�����o�[���N���b�N���ACTRL�L�[�{SHIFT�L�[�{ENTER�L�[�������Ĕz����������B
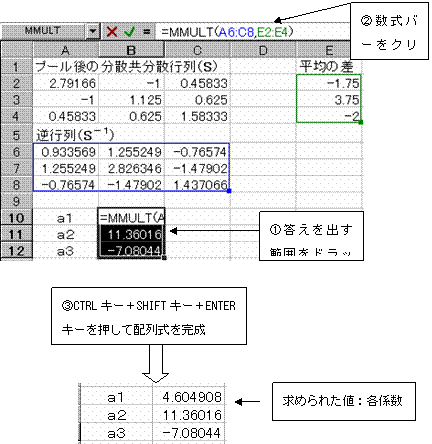
������
a1=4.605�@a2=11.36�@a3 =�|7.08
![]() ����Đ��`���ʎ��́A�x��4.605��w1�{11.36��w2�|7.08��w3�|49.25
����Đ��`���ʎ��́A�x��4.605��w1�{11.36��w2�|7.08��w3�|49.25
�S�D�R�@���ʕ��͂ɂ�����2�Q�̕ꕽ�ς̍��̌�������{
4.3.1�@�Q�P�̒��S����Q�Q�̒��S�܂ł̃}�n���m�r�X�̋��������߂�B
�Q�P�̒��S����Q�Q�̒��S�܂ł̃}�n���m�r�X�̋����c02��

4.3.2�@�Q�Q�̕ꕽ�ςɍ������邩�ǂ�����������{����B
�A�������F�g0�F��1����2 �i�Q�Q�̕ꕽ�ς͓������j
�Η������F�g1�F��1����2 �i�Q�Q�̕ꕽ�ς͓������Ȃ��j
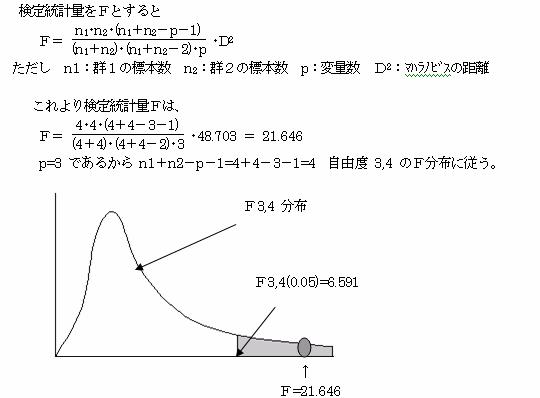
�e���e3,4(0.05) �ł���A���p��ɓ���B����ĂQ�Q�̕ꕽ�ς͓������Ƃ������������p���@�@��B�Q�Q�̕ꕽ�ςɍ�������B
�S�D�S�@�E�B���N�X�̃��i�����_�j���v�ʂ��g�p���āA�Q�Q�Ԃ̕ꕽ�ς̍��̎��{�B
�@�Q�P�i�`�ƊE�j�̂R�ϗʂ̕����a�E�Ϙa�s����r1�A�Q�Q�i�a�ƊE�j�̂R�ϗʂ̕����a�E�Ϙa�s����r2�A�Q���̐Ϙa�E�����a�s���rW�Ƃ���B
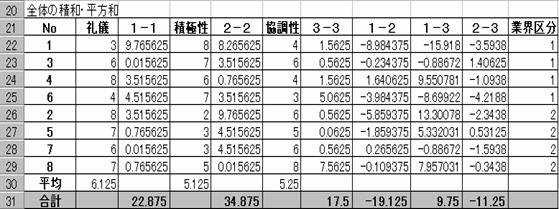
�ȏ���܂Ƃ߂��

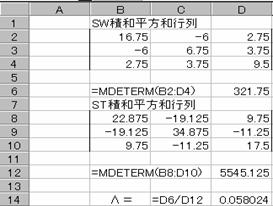
�b�rW�b��321.75
�S�̂̕����a�E�Ϙa�s��(�rT)

�b�rT�b��5545.12
�ȏォ�烩���v�ʂ́A�����b�rW�b���b�rT�b
����321.75��5545.12��0.05802

�����v�ʂ��狁�߂����蓝�v�ʂƁA�}�n���m�r�X�̋������狁�߂����蓝�v�ʂ͈�v
����B
�S�D�T�@�딻�ʂ̊m��

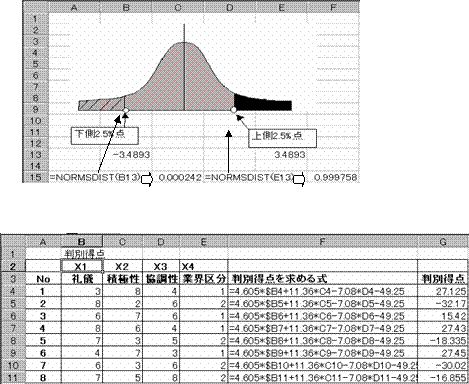
�W�����K���z�Ɋւ����
![]() �@�@�y�l����m�������߂�@�c�@=normsdist(Z�l)
�@�@�y�l����m�������߂�@�c�@=normsdist(Z�l)
�@�@�m������Z�l�����߂�@�c�@=normsinv(�m��)
���ϑ����ꂽZ�l=3.4893�ł���B���̎��̊m���l�́@=normsdist(3.4893)=0.999758
�ƂȂ�B����͉��}�̊D�F�����̒l�i�|������3.4893�j�܂ł̊m���l�ł���A����Ɏg�p����㑤�m���l�́A1�|�@0.999758=0.000242�̒l���g�p����B���K���z�͋���ł��邩��A����2.5%��Z�l(�|3.4893)���g�p����A�����l�邱�Ƃ��ł���B=normsdist(3.4893)=0.000242
�딻�ʂ̊m����0.024%�ł��邱�Ƃ�������B
�S�D�U�@���ʓ��_�����߂�
���ʓ��_�́A���ʎ��@�x��4.605��w1�{11.36��w2�|7.08��w3�|49.25 �ŋ��߂�B
|
�ԍ� |
���ʓ��_ |
||
|
���ʓ��_������ƁA�`�ƊE�̎Ј��i�Q�P�j�́{�l�ɁA�a�ƊE�̎Ј��i�Q�Q�j�́|�l�ɂȂ��Ă��邱�Ƃ�������B 2 3 4 5 6 7 8 |
27.12 �|32.17 15.42 27.43 �|18.335 27.45 �|30.02 �|16.85 |
�S�D�V�@�悢���ʎ����쐬����B
�悢���ʎ��́A���Ȃ��ϗʂōŗǂ̔��ʌ��ʂ��锻�ʊ������߂邱�Ƃł���B �ϐ������@�ōŗǂ̔��ʎ������߂�B
�ϐ������@�ł́A�g�p����ϐ������X�ɑ��₵�Ă������@�ł���B
�S.7.1�@�ŏ���3�ϗʂ̂����A���ʎ��ōł���^���Ă���ϗʂ��̗p����B�ł���^���Ă���ϗʂ͌��蓝�v��F�l�̍ł��傫�Ȓl��^����ϗʂł���B
�ϗʂ��P���g�p�������̃}�n���m�r�X�̔ċ��������߂�B
�u�ϗ�X1�̂ݎg�p�������̃}�n���m�r�X�̔ċ����v

A�Q�EB�Q�̊e�s�Ε��U�����ŋ��߂�B�s�Ε��U�����߂���́@��VAR(�͈�)�ł���B
A�Q�EB�Q�̕W�{���͂Ƃ��ɂS�ł���B���ꂩ��v�|����̕��U�����߂�B

����X1�̌W����2�Q�̕��ς̍���������}���n�m�r�X�̔ċ��������߂���B
D02 = (�|0.62687)�~(�|1.75)=�|1.097015
�@���l�ɂ��āAX2�ϗʂ݂̂��g�p�������AX3�ϗʂ̂ݎg�p�������̂��ꂼ��̃}�n���m�r�X�̔ċ��������߂�B�����쐬���Ă����AX2�̕ϗʂ��R�s�[��������ɍČv�Z����āAX2���g�p�������̃}�n���m�r�X�̔ċ��������߂���B
�u�ϗ�X2�̂ݎg�p�������̃}�n���m�r�X�̔ċ����v
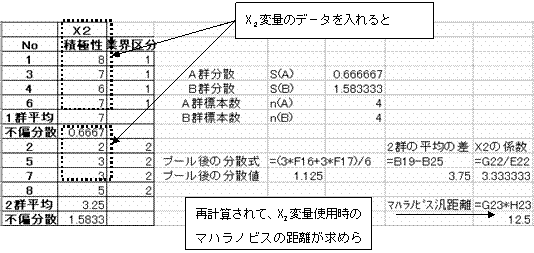
�u�ϗ�X3�̂ݎg�p�������̃}�n���m�r�X�̔ċ����v

�ȏォ��e�ϗʂ��P�g�p���̃}�n���m�r�X�̔ċ�����
![]() �@�@�@X1�ϗʎg�p���̃}�n���m�r�X�̔ċ����F1.097
�@�@�@X1�ϗʎg�p���̃}�n���m�r�X�̔ċ����F1.097
�@�@�@X2�ϗʎg�p���̃}�n���m�r�X�̔ċ����F12.5
�@�@�@X3�ϗʎg�p���̃}�n���m�r�X�̔ċ����F2.526
�e�ϗʂP�g�p�������̌W�������ɗ����̌��蓝�v��F��
![]()

![]()
�@�@ X1�ϗʎg�p����F�l�F2.194
�@�@ X2�ϗʎg�p����F�l�F25
�@�@ X3�ϗʎg�p����F�l�F5.053
���ꂼ��̊e�ϗʂ��P�g�p���ē���ꂽ���`���ʎ��̂e�l�ōő�̂e�l��^����̂́A�@�@�@�ϗʂw2���g�p�������ł���̂ŁA�܂��ϗʂw2���̗p����B
 ����āA���`���ʎ��́A�x��3.333��w2�|17.0833�Ƌ��߂���B
����āA���`���ʎ��́A�x��3.333��w2�|17.0833�Ƌ��߂���B
���̎��̂Q�Q�̒��S�Ԃ̃}�n���m�r�X�̋�����12.5�ł���̂ŁA���ꂩ��ϗʂw2�������@�@�@�g�p�������̐��`���ʎ��Ŕ��ʂ����Ƃ��A���̌W�������ɗ����ǂ������肷��B
���蓝�v�ʂ��e�Ƃ���Ƃe��25.0
���R�x�́A1,4�{4�|1�|1=6 �ł���B

�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�@��
�e��25.0
�L�א�����=0.05��
�e=25.0 ��
�e1,6(0.05)=5.978 �ł��邩��A�W����2���O�ł���B
4.7.2�@�Q�Q�̑��֔�����߂āA���֔�̌�����s���B
���܍��i�Q�E�s���i�Q�ɌQ��������ƈȉ��̂悤�ȕ\�ɂȂ�B
|
|
�m�n |
�w1 |
�w2 |
�w3 |
|
�� �e �Q |
�P �R �S �U |
�R �U �W �S |
�W �V �U �V |
�S �U �S �R |
|
�s �� �e �Q |
�Q �T �V �W |
�W �V �U �V |
�Q �R �R �T |
�U �T �U �W |
�ϗʂw1�ɂ��č��i�Q�E�s���i�Q�ɕ������
|
|
�m�n |
�w1 |
|
�� �e �Q |
�P �R �S �U |
�R �U �W �S |
|
�s �� �e �Q |
�Q �T �V �W |
�W �V �U �V |
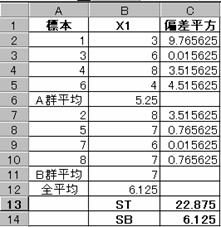
�S�ϓ����rT�A�Q�Q�Ԃ̋��ԕϓ����rB�Ƃ����
�rT��22.875 �rB�� 4�~(5.25�|6.125)2 �{ 4�~(7�|6.125)2 = 6.125
����ă�2���rB���rT��0.26776
![]()
F=2.194�̎��̊m���l�́A��FDIST(F�l�A���R�x1�A���R�x2)���狁�߂�B
�����R�x1�F1�@�@���R�x2�F6�ł��邩��
|
F�l |
F�l�� |
�m�� |
|
2.194 |
=FDIST(E2,1,6) |
0.189054 |
|
25 |
=FDIST(E3,1,6) |
0.002452 |
|
5.053 |
=FDIST(E4,1,6) |
0.065631 |
���l�ɕϗʂw2�ɂ��č��i�Q�E�s���i�Q�ɕ����A�S�ϓ��E���ԕϓ������2��0.80645�ł��邩��e��25�B�ϗʂw3�ɂ��č��i�Q�E�s���i�Q�ɕ����A�S�ϓ��E���ԕϓ������2��0.457143
�@�e��5.053�@�Ƌ��߂���B
�S.7.3 �ϗʂw2���̗p�����̂ŁA���ɕϗʂ��P���₵�Ăe�l����������B
�@�ϗʂ����������A���̕ϗʂ��̗p���邩�ǂ����̖ڈ��Ƃ��āAF�l�����߁A���̒l��2�ȏ�ł���̗p����悤�ɂ���B
(�P)�ϗʂw2�ɕϗʂw3����������
���`���ʎ��́A�x=5.1685��w2�|3.30337��w3�|9.14607
���̎��̂Q�Q�̒��S�Ԃ̃}�n���m�r�X�����́A25.989�ł���B
���̐��`���ʎ��̕ϗʂw3�̌W����3�����ʂɖ𗧂��ǂ�����������{����B
��3���O�i�ϗʂw3�̌W����3�͖��ɂ����Ȃ��j�Ƃ��������̂��Ƃ�
���蓝�v�ʂ��e�Ƃ����
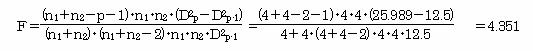
�ϗʂw2���g�p�������`���ʎ��ŁA�Q�Q�ɔ��ʂ����Ƃ��̂Q�Q�̒��S�Ԃ̃}�n���m�r�X�̋����@�͂c2 ��12.5�B�ϗʂw2�Ƃw3���g�p�������`���ʎ��ŁA�Q�Q�ɔ��ʂ����Ƃ��̂Q�Q�̒��S�Ԃ̃}�n���m�r�X�̋�����
�c2 ��25.989
F�l:4.351�ł���̂ŁAX2�ɕϗ�X3�����������͍̗p����B
(�Q)�ϗʂw2�ɕϗʂw1����������
���`���ʎ��́A�x=0.832117��w1�{4.07299��w2�|0.259708
���̎��̂Q�Q�̒��S�Ԃ̃}�n���m�r�X�����́A13.818�ł���B
���̐��`���ʎ��̕ϗʂw1�̌W����1�����ʂɖ𗧂��ǂ�����������{����B
��1���O�i�ϗʂw1�̌W����1�͖��ɂ����Ȃ��j�Ƃ��������̂��Ƃ�
���蓝�v�ʂ��e�Ƃ����

�ϗʂw2���g�p�������`���ʎ��ŁA�Q�Q�ɔ��ʂ����Ƃ��̂Q�Q�̒��S�Ԃ̃}�n���m�r�X�̋����@�͂c2 ��12.5�B�ϗʂw2�Ƃw1���g�p�������`���ʎ��ŁA�Q�Q�ɔ��ʂ����Ƃ��̂Q�Q�̒��S�Ԃ̃}�n���m�r�X�̋�����
�c2 ��13.818
F�l:0.425�ł���̂ŁAX2��X1�̕ϗʂ����������͍̗p���Ȃ��B
�ȏ�̕ϐ������@�ɂ��ŗǂ̐��`���ʎ��́A�x=5.1685��w2�|3.30337��w3�|9.14607�ł���B
�S�D�W�@���߂����`���ʎ����g�p���A���ʂ�\������B
�@�@���܂`�ƊE�E�a�ƊE�̋ƊE�敪�s���̐l���K��Ă������A���̐l�̈�ۂ��A
�w1�i��V�j���U�@�w2�i�ϋɐ��j���T�@�w3�i�������j���U �ł������Ƃ���Ƃ��̐l�͂`�ƊE�E�a�ƊE�̂ǂ���̐l�ł���Ɣ��ʂł��邾�낤���H
�R�ϗʂ��g�p�������̐��`���ʎ����g�p�����
�@���`���ʎ��́A�x��4.6049��w1�{11.3601��w2�|7.08042��w3�|49.2635
�@�@�x��4.6046�~6�{11.3601�~5�|7.08042�~6�|49.2535 = �|7.30792
����āA�a�ƊE�̎Ј��ƍl������B
�ϐ��I��@�ŋ��߂��A�ŗǂ̐��`���ʎ����g�p�����
���`���ʎ��́A�x=5.1685��w2�|3.30337��w3�|9.14607
�ł��邩��A
�x��5.1685�~5�|3.30337�~6�|9.14607= �|3.12379
����āA�a�ƊE�̎Ј��ƍl������B