1.回帰分析
何名かの体重と身長の値が分かっているとき、体重の値は分かっているが、身長が不明の人がいるとする。このようなとき、すでに得ているデータから身長と体重の関係を調べ、その相関を求め、身長不明の人の身長を予測する。この様な分析方法を回帰分析という。
求めるものは身長であり、これを目的変量と呼ぶ。身長の値を予測するのは、体重からであるので、この体重のことを説明変量と呼ぶ。説明変量が1つの時を単回帰分析といい、説明変量が2つ以上の時を多重回帰分析という。
回帰分析では、説明変量は量的データであり、また目的変量も量的データである。
なお、回帰式で予測をするときには、説明変量の範囲内で予測することが望ましい。説明変量の範囲を大きく越えたところで予測すると誤差が大きくなり実用に適さなくなる。
1.1 単回帰分析
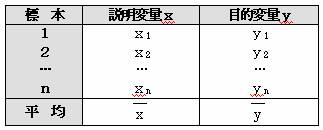
正規母集団から抽出して得られた標本データx・yが下表のようにあり、x・y間にある関係があるものとする。
|
標 本 |
説明変量x |
目的変量y |
|
1 2 … n |
x1 x2 … xn |
y1 y2 … yn |
以上の標本データをXYグラフで描くいて、下のようになったとする
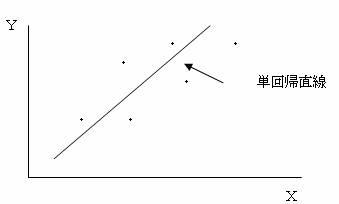
標本データx・yの間には右上がりの関係がありそうなので、xとyの関係を表す適当な直線を考える。 目的変量yと説明変量xとの間に相関があるとき、
Y=b1・x+b0 なる直線を1本考え、実データとこの直線上の値との差をεとする。
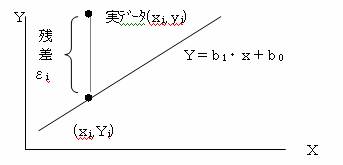
Y=b1・x+b0 なる直線は全ての標本データについて、
その残差が最小になるようにひく必要がある。この直線から各標本データとのズレ具合いを計るために、各残差の平方和をとり、この平方和を最小にするようにする。このような方法を最小2乗法という。
標本データは、直線Y=b1・x+b0 から残差(ε)分ずれているので、標本データは
y=b1・x+b0 +εと表す。
このことから線形回帰モデルを
yi=β1・xi+β0+εi (i=1,2…n)とすると
残差εについて、
①εiとεjはお互いに独立であり、正規分布 N(0,σ2)に従う。
②εiの平均値(期待値)は0である。
③εiの分散は一定である。
このような仮定下で単回帰式を Y=b1・x+b0 とする。
いま、残差εに注目すると εi=yi-Yi εi=yi-b1・xi-b0 である。
この残差を全ての標本データについて合計し、その合計値を最小にするようなb0・b1 を求め、この単回帰式を得る。
∑εi2 =∑(yi-b1・xi-b0)2 であるから
f=∑(yi-b1・xi-b0)2とすると
この式をb0,b1で偏微分して、0とおくことにより、正規方程式を得て、式fを最小 にするb0・b1を得ることができる。
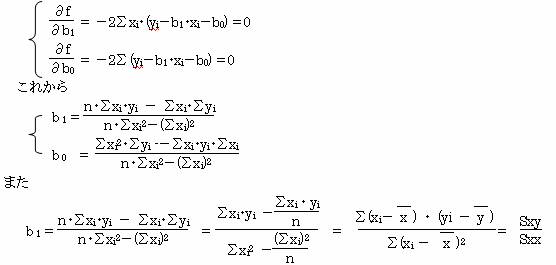
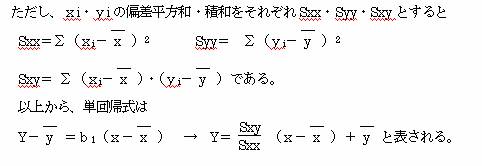
またxとyの相関係数をRxyとすると

1.2 重回帰分析
それでは次に説明変量がx1・x2の2変量になったときの回帰式を求める。
|
標 本 |
説明変量x1 |
説明変量x2 |
目的変量y |
|
1 2 … n |
x11 x12 … x1n |
x21 x22 … x2n |
y1 y2 … yn |
説明変量が2変量あるので、単純に説明2変量(x1とx2)の平均値をとって、その値と目的変量(y)との相関を求めても、平均値をとる段階で失う情報量が大きいので正しい回帰式を得ることができない。
このように説明変量が2つ以上ある時の回帰分析を重回帰分析という。
1.2.1 重回帰式を求める。
2説明変量が次のようになっているときの重回帰直線を求める。

この関係を図で表すと
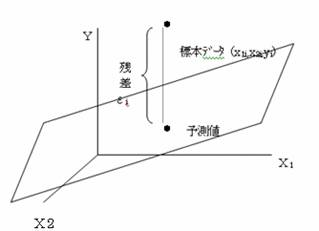
説明変量(x1,x2)と目的変量(y)との間に相関関係があるとき
Y=b1・x1+b2・x2+b0
なる平面を考え、実際の標本データからこのこの平面上への残差をεとすると
説明変量が2つある時の重回帰式は
yi=b1・x1i+b2・x2i+b0+εi と表される。
残差εに注目すると εi=yi-Yi
εi=yi-(b1・x1i+b2・x2i+b0)であるから
この残差平方和を求め、残差平方和が最小にするようなb0・b1・b2 を求めると、重回帰式を得ることができる。
一般に説明変量がp個ある時の線形重回帰モデルは
yi=β1・x1i+β2・x2i+…+βp・xpi+β0+εi (i=1,2 …n)
と表される。この時単回帰分析と同様に
残差εについて、
![]() ①εiとεjはお互いに独立であり、正規分布 N(0,σ2)に従う。
①εiとεjはお互いに独立であり、正規分布 N(0,σ2)に従う。
②εiの平均値(期待値)は0である。
③εiの分散は一定である。
との仮定下で重回帰予測式を
Yi=b1・x1i+b2・x2i+…+bp・xpi+b0 とする。
b1・b2…bpを偏回帰係数といい、 β1・β2…βp を母偏回帰係数という。
[残差平方和∑(εi)2 を最小にするようなb0・b1・b2 を求める。]
∑(εi)2 =∑{yi-(b1・x1i+b2・x2i+b0)}2 を最小にするb0・b1・b2 を
求める。
f=∑(yi-b1・x1i-b2・x2i-b0)2 とし、この式をb0・b1・b2で偏微分する。
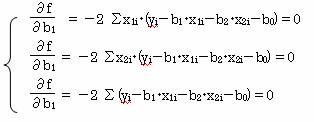
これより
![]() ∑x1i・(yi-b1・x1i-b2・x2i-b0)=0 …①
∑x1i・(yi-b1・x1i-b2・x2i-b0)=0 …①
∑x2i・(yi-b1・x1i-b2・x2i-b0)=0 …②
∑(yi-b1・x1i-b2・x2i-b0)=0 …③
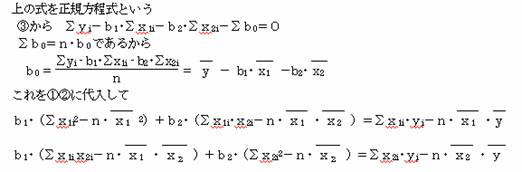
これよりb0・b1・b2 を求めると、重回帰式の係数を得ることができる。
1.2.2 偏差平方和・積和から重回帰式を求める
(1)説明変量が2個の時
説明変量x1・x2 の偏差平方和それぞれS11・S22、偏差積和をS12とすると
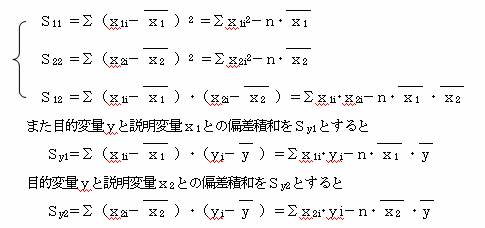
以上から前の式は
![]() S11・b1+S12・b2=Sy1
S11・b1+S12・b2=Sy1
S12・b1+S22・b2=Sy2
となるので、これから係数b0・b1・b2を求める。
![]()
(2)説明変量がp個ある時
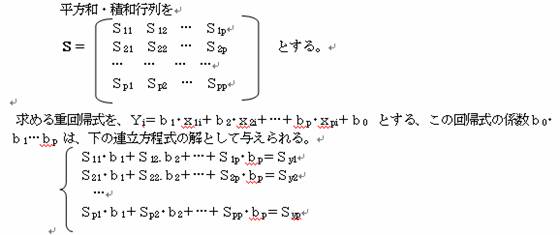
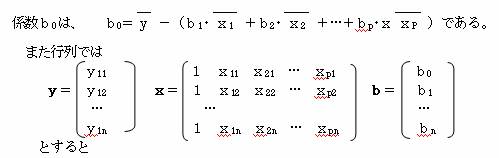
係数bは、
b=(x’・x)-1・x’・y で求めることができる。
1.3 標準偏回帰係数
説明変量がどれくらい目的変量に影響を与えているか(寄与しているか)を見るには、求めた重回帰式の偏回帰係数を見ればよい。通常、偏回帰係数が大きいほど目的変量に与える影響が大きいので多く寄与しているといえる。しかし、説明変量間で単位が異なるときには、単位の影響を受けるので、単純に偏回帰係数の大小比較して決めることはできない。単位の影響を除くには、標本データを標準化する。データを標準化することにより、平均=0・分散=1となり単位の影響を受けなくなるので、標準化したデータから偏回帰 係数を求めるようにする。このように標準化したデータから得られた偏回帰係数を、標準 偏回帰係数という。
標準偏回帰係数の大きいほど、目的変量に与える影響が大きく、寄与の大きい変量である といえる。
通常説明変量が2つの時の重回帰式は

1.4 相関係数と決定係数
1.4.1 単回帰式における相関係数と決定係数
説明変量xの変化に従って目的変量yが変化する(相関関係にある)ときxとyの間の相関係数をRとすると

いま説明変量xと実測値yとの関係がrである時、これから求めた単回帰式を
Y=b1・x+b0 とすると
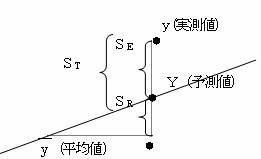
実測値yは、単回帰直線の付近にばらついて散在している。このばらつきの小さいほど単回 帰式のあてはまりがよい(精度が高い)直線といえる。また説明変量xの目的変量に与える影響が大きいといえる。つまり決定力が大きいといえる。
分散状況を見ると、全分散(ST)は、実測値yiが平均値yからどれ位分散しているかであるので、![]() 回帰で説明可能な部分の分散(SR)、つまり予測値が平均値からどれ位分散しているかは、
回帰で説明可能な部分の分散(SR)、つまり予測値が平均値からどれ位分散しているかは、![]() 回帰で説明できない残差部分の分散(SE)つまり実測値が予測値からどれ位分散しているかは、∑(yi-Yi)2である。
回帰で説明できない残差部分の分散(SE)つまり実測値が予測値からどれ位分散しているかは、∑(yi-Yi)2である。
これらの変動の間には、
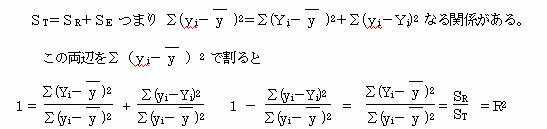 このR2 のことを決定係数という。この決定係数は 0≦R2≦1の値をとる。
このR2 のことを決定係数という。この決定係数は 0≦R2≦1の値をとる。
また、この決定係数R2は相関係数Rの2乗に等しい。
1.4.2 重回帰式における相関係数と決定係数
(1)重相関係数と決定係数

重相関係数Rは、実測値データyと重回帰式から求めた予測値データYとの相関係数である。
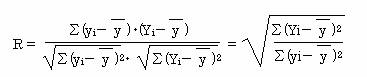
また単回帰のときと同様に、相関係数の2乗を決定係数と呼び、やはり0≦R2≦1の値をと る。R2 が1に近いほど重回帰式の精度が高いといえる。
![]()
[重相関係数の検定]
標本から得られた重相関係数について、その母重相関係数(ρ)が無相関かどうかの検定を 行う。標本から得られた重相関係数をRとする時、その母相関係数(ρ)についてρ=0の仮説につき、検定統計量をFとすると
![]() は、自由度p,n-p-1のF分布に従うことを利用して検定を行う。
は、自由度p,n-p-1のF分布に従うことを利用して検定を行う。
検定をおこなう
(1)仮説をたてる
仮 説 H0:ρ=0 (母重相関係数は無相関である)
対立仮説 H1:ρ≠0 (母重相関係数は無相関ではない)
(2)検定統計量Fは自由度p,n-p-1のF分布に従う。
(3)有為水準αで検定を実行する。
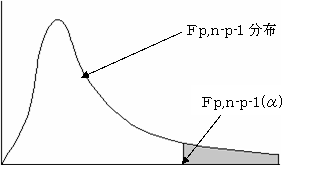
F≧Fp,n-p-1(α)であれば、仮説を棄却する。つまり、母重相関係数は有効であり、実測値と予測値の間には相関があるといえる。
重相関係数は、実測値yと予測値Yとの相関係数である。これに対して単純に2変量間の相関係数を単相関係数という。多変量データにおいて、2変量間の相関係数が本当に正しい相関を示すとは限らない。多変量においては2変量間の相関係数を求めても、その2変量以外の変量がこの2変量に影響を与えるからである。よって、多変量間における2変量の正しい相関係数を求めるには、相関係数を求める2変量以外の変量の影響を取り除いて(一定にして)相関係数を求める必要がある。このようにして求めた相関係数を偏相関係数という。
(2)偏相関係数
多変量データにおいて、任意の2変量間の単純な相関係数を単相関係数というが、これは相関をとる2変量以外の変量が、その2変量に影響を与えている相関係数である。これに対し、相関を求める2変量以外の他の変量の影響を取り除いた2変量間の相関係数を偏相関係数という。
いまP変量の任意の2変量間の単相関係数をrijとする。
|
|
x1 x2 … xp |
|
x1 x2 … xp |
r11 r21 … rp1 r21 r22 … rp2 … rp1 r2p … rpp |

(3)自由度調整済み決定係数
決定係数や重相関係数は、説明変量の数を増やすと単純に増加する傾向がある。
そこで、単純に説明変量の数を増やしても、決定係数が単純に増加しないように調整した自由度調整済み決定係数という。通常標本数がn個、説明変量がn-1個のものは分析することができない。必ず説明変量がn-2個以下にする必要がある。
自由度調整済み決定係数をR’2 とすると

1.5 回帰式の信頼性
回帰式を使用して説明変量から目的変量の値を予測する時、その予測値がどのくらい信頼性があるのかを検定する方法に、分散分析を用いる方法と相関係数を用いる方法がある。
1.5.1 分散分析を用いる場合
(1)単回帰のとき
説明変量xと実測値yと単回帰式から求めた予測値Yが下表のようである時
|
標 本 |
説明変量x |
実測値y |
予測値Y |
|
1 2 … n |
x1 x2 … xn |
y1 y2 … yn |
Y1 Y2 … Yn |
予測値Yiは、Y=b1・x+b0の回帰式から求めた値
以上のデータをもとに、分散分析表を作成し回帰式の信頼性を検定する。
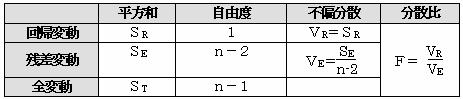
全体の変動(ST)を、回帰による変動(SR)と残差による変動(SE)とに分け、回帰による変動が残差による変動よりも小さいようであれば、回帰直線で求めた予測値は残差による影響の方が大きいので予測には役立たないと考える。
実測値の変動(ST)=回帰による変動(SR)+残差による変動(SE)
残差が小さいほど「実測値の変動」≒「回帰による変動」となり、よい予測値を得られる。
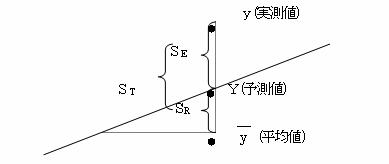
(1)変動を求める
①実測値の全変動(ST)…実測値の各値yiが、実測値の平均![]() からどれ位ばらついているかである。
からどれ位ばらついているかである。 ![]()

右片側検定を行い、VRがVEより大きいかどうか検定する。VR>VEであれば、回帰による変動が残差による変動よりも全変動に与える影響が大きいので、回帰直線は予測に役立つといえる。
(5)検定を行う
(1)仮説をたてる
仮 説
H0:回帰直線は予測に役立たない(VR≒VE)
対立仮説
H1:回帰直線は予測に役立つ(VR>VE)
(2)検定統計量Fを求める
![]() は自由度1,n-2のF分布に従う
は自由度1,n-2のF分布に従う
(3)有為水準αで右片側検定を行う
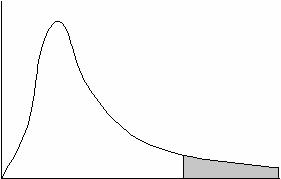
F1,n-2 分布
![]()
↑
F1,n-2 (α)
F≧F1,n-2 (α)であれば、仮説H0を棄却し、対立仮説H1:回帰直線は予測に役立つを採択する。つまり、この回帰直線は予測に役立つとする。
以上をまとめて分散分析表を作成する。
分散比Fは自由度1,n-2のF分布に従う
(2)重回帰のとき
説明変量がP個ある時の多変量データが下のようになっているとする
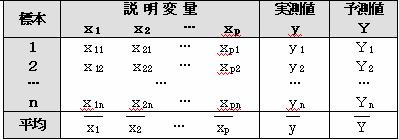
予測値はY=b1・x1i+b2・x2i+…+bp・xpi+b0 から得た値
n:標本数 p:説明変量の個数
単回帰同様に、全体の変動を回帰による変動と残差による変動とに分け、分散分析表を作成し重回帰式の信頼性を検定する。
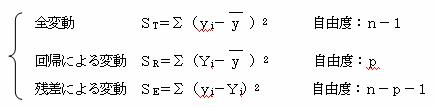
変動の関係 ST=SR+SE
以上をまとめて、分散分析表を作成すると
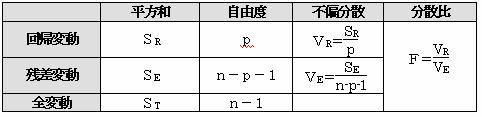
分散比Fは、自由度p,n-p-1のF分布に従うので、これを利用して単回帰の場合と同様に回帰式の信頼性を検定することができる。
分散分析では、回帰式の信頼性を検定することはできるが、どれ位信頼できるかについては不明である。
1.5.2 相関係数を用いる場合
相関係数Rの2乗は決定係数と呼ばれているが、この決定係数を利用して回帰式の信頼性を見る。

となり、分散分析のF値が重相関係数の検定の検定統計量と一致する。
1.6 標準誤差(SE:Standard
Error)
標準誤差とは、推定値の標準偏差(SD)をいう。
いま、標本n1個から得られた回帰式を Y1=b11・x11+b21・x21+…+bp1・xp1
次の標本n2個から得られた回帰式を Y2=b12・x12+b22・x22+…+bp2・xp2
以下同様にしてこれを何回か繰り返すと係数b1 は正規分布に従うことが分かっている。同様にb2…bpについてもそれぞれ正規分布に従う。この時の標準偏差を標準誤差という。
1.6.1 標準誤差を求める
(1)単回帰の時
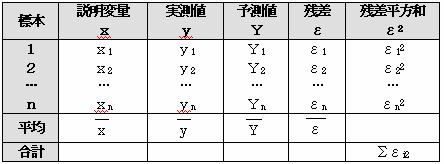

(2)重回帰の時
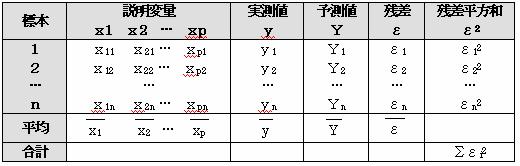
重回帰式をYi=b1・x1i+b2・x2i+…+bp・xpi+b0 とすると
残差はεi=yi-Yiで、残差平方和(SE)は
∑εi2=∑(yi-Yi )2
自由度は、n-p-1
不偏分散は VE=SE/(n-p-1)
説明変量の偏差平方和積和行列をSであらわすと
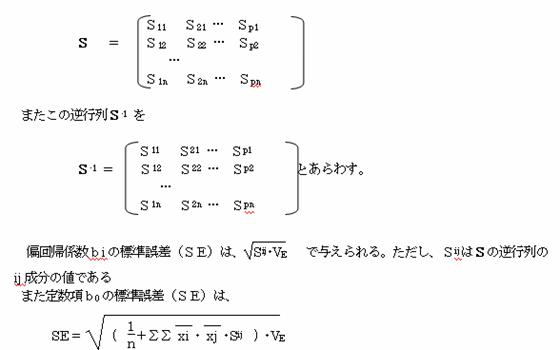
1.7 偏回帰係数の検定
標本から得られた回帰式の信頼性については、分散分析を行うことにより検定することができる。回帰式が予測に役立つとしたとき、次に偏回帰係数が有効かどうか検定し、有効でない偏回帰係数は予測結果に影響を与えていないので、使用しなくてもよい係数ということになる。
いま、重回帰モデルを、yi=β1・x1i+β2・x2i+…+βp・xpi+β0+εi (i=1,2 …n)とするとき
残差εについて、
![]() ①εiとεjはお互いに独立であり、正規分布 N(0,σ2)に従う。
①εiとεjはお互いに独立であり、正規分布 N(0,σ2)に従う。
②εiの平均値(期待値)は0である。
③εiの分散は一定である。
との仮定下で重回帰予測式を
Yi=b1・x1i+b2・x2i+…+bp・xpi+b0 とする。
母偏回帰係数βi=0を検定することにより、その偏回帰係数が予測結果に影響を与えうる係数かどうかの検定を行う。
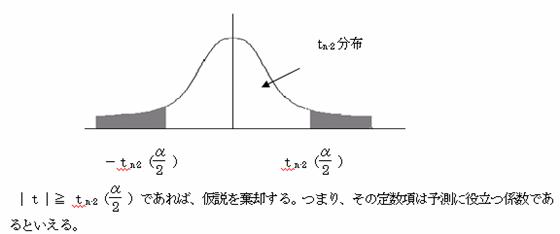
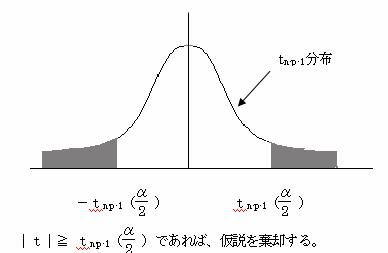
1.7.1 単回帰における回帰係数および定数項の検定
単回帰式を Y=b1・x+b0 とする。
(1)回帰係数b1の検定

(1)仮説をたてる
帰無仮説 H0:β1=0 (説明変量xの母回帰係数は0である)
対立仮説 H1:β1≠0 (説明変量xの母回帰係数は0でない)
(2)検定統計量tを求める
![]()
(3)有為水準αで両側検定を行う

(1)仮説をたてる
帰無仮説
H0:β0=0
対立仮説
H1:β0≠0
(2)検定統計量tは、自由度n-2のt分布に従う
(3)有為水準αで両側検定を行う
1.7.2 重回帰における偏回帰係数および定数項の検定
重回帰式をYi=b1・x1i+b2・x2i+…+bp・xpi+b0 とする
(Ⅰ)偏回帰係数biの検定
検定統計量をtとする
![]()
ただし、SE:偏回帰係数biの標準誤差
(1)仮説をたてる
帰無仮説
H0:βi=0 (説明変量xiは予測に役立たない)
対立仮説
H1:βi≠0 (説明変量xiは予測に役立つ)
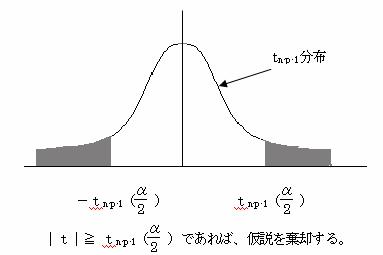
(2)検定統計量tは自由度n-p-1のt分布に従う
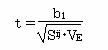
(3)有為水準αで両側検定を行う
(2)定数項b0の検定
検定統計量をtとする

(1)仮説をたてる
帰無仮説 H0:β0=0 (定数項は予測に役立たない)
対立仮説 H1:β0≠0 (定数項は予測に役立つ)
(2)検定統計量tは自由度n-p-1のt分布に従う
(3)有為水準αで両側検定を行う
1.8 多重共線性について
説明変量間においてお互いに高い相関がある時、偏回帰係数を求めることができないという現象を引き起こす。これを多重共線性という。説明変量間でお互いに高い相関があるということは、どちらも同じことを説明している変数なのでどちらか一方の変量があればよいといえる。重回帰式を求めるにあたり、多重共線性があるときにはどちらかの説明変量を落として求める必要がある。
多重共線性の有無については、
(1)説明変量間の単相関係数を求め、単相関係数が1または-1に近いものがあれば多重共線性がある。
(2)多重共線性が認められるときには、偏回帰係数を求められないとか、偏回帰係数の符号と、説明変量と目的変量の単相関係数の符号が一致しない等の現象を起こす。
多重共線性の例(1)
|
標本 |
説 明 変 量 |
目的変量 |
||
|
x1 |
x2 |
x3 |
y |
|
|
1 2 3 4 5 6 |
5 5 7 5 8 12 |
4 4 5.6 4 6.4 9.6 |
8 5 6 2 7 14 |
32 36 48 44 52 70 |
上記表から、説明変量間の相関行列を作成すると

x1-x2の相関係数が1であり、偏回帰係数を求めることができない。
x2=x1×0.8 となっており、x2変量は目的変量yに何の寄与もしていないので不用な変量であるといえる。x1変量を使うとき、x2変量を落として回帰式を求めなければならない。
1.9 良い重回帰式を作成する
重回帰式は、いくつかの説明変量から目的変量の値を予測するが、説明変量をむやみに多くしても無駄なことが多い。理想的な重回帰式は、なるべく少ない説明変量でなおかつ誤差の小さな目的変量を得られるような式である。このためには説明変量を調べ、回帰式に必要な変量であるかを検討する必要がある。
(1)説明変量の選択基準
(1)目的変量に与える影響の大きい説明変量を選ぶ。各説明変量と目的変量間の単相関係数を求め、各説明変量の目的変数に与える影響の大きさを調べる。
(2)説明変量間で高い相関が認められるときには、どちらか一方の変量を落として重回帰式を作成する。一般に説明変量間の単相関係数が0.9以上ある時にはどちらか一方の説明変量を落とす。特に説明変量間で単相関係数≒1の時には偏回帰係数を求めることができない。
(3)偏回帰係数≒0となるような説明変量は、役にたたない変量であるから落とすようにする。
(2)重回帰式の良さを評価する方法
いくつかの説明変量を使用して何種類かの重回帰式を作成したとき、それらの重回帰式の中で、どの重回帰式が一番よい回帰式であるかを判断する基準としてAIC(赤池の情報量基準)がある。AICは
AIC=n・(loge2π+1)+n・loge・ +2・(p+2)
で与えられる。
但しn:標本数 p:説明変量の個数 SE(残差平方和):∑(yi-Yi)2
AICの値は小さいほど当てはまりがよいとされているが、絶対的基準を与えるものでは ないので、どの値以下が良いとはいえない。あくまでの、いくつかの説明変量を組み合わせて作成した回帰式のそれぞれのAIC値を求め、それらの回帰式の中でAIC値が最も小さいものが一番良い回帰式であると判断する。
1.10 変数選択法
説明変量がいくつかある時、どの変量を使用すれば最良の重回帰式を得ることができるかを解決するために、変数選択法がある。
(1)総あたり法
説明変量がP個あるとき、このP個の全ての組合せ(2P-1通り)について回帰式を作成し、回帰式の検討する方法。この方法では説明変量の個数が増えると作成する回帰式が膨大になり、実用的ではない。
(2)逐次選択法(ステップワイズ法)
①変数増加法…変数0から出発し、順次変数を増やしていく方法
②変数減少法…全説明変量使用した回帰式から出発し、順次変数を減少させていく方法
③変数増減法…変数0から出発し、順次変数を増やしていくが、一度取り込んだ変数でもある基準を満たさなくなったときには落としてしまう方法
④変数減増法…全説明変量使用した回帰式から出発し、順次変数を減少させていくが、一度落とした変量についてもある基準を満たすときには再度採用する方法
[偏回帰係数のF値を使用したステップワイズ法]
(1)変数増加法
①変数0から出発する。
②目的変量yと各説明変量x1…xpとの単相関係数を求め、この中で最も相関係数の大きい変数を取り込む。
または、単相関係数を求める代わりに、y-x1 … y-xpと2変量ずつの回帰式を 作成し、それぞれの偏回帰係数をみて、そのF値が最も大きく、なおかつF値が2以上(自由度に関係なく)の変数を取り込む。なお、全偏回帰係数のF値が2以下の時には取り込むべき変数はないとする。
いま、x1を採用するとするとY=b1・x1+b0の式ができる。
③次に②で採用した変量以外の変量を1つ追加して回帰式を作成する。
それぞれの回帰式について、その偏回帰係数のF値を求め、最大のF値を与えかつ自由度に関係なくその値が2以上のものがあれば、2番目の変量として採用する。
以下全変量についてこれを繰り返し実行する。
寄与率R2 をそれぞれ求めて寄与率が最も大きいものを採用してもよいが、寄与率は、使用する変量の個数が増えると単純に増加する傾向があるので、寄与率が余り向上しないときには採用しない方がよい。
④変数増加の打ち切り
全ての変数について実行が終了し、もう取り込むべき変量がなくなったとき。
または、最初に決めた打ち切りの決定値(R2)以下になったとき。
(2)変数減少法
①最初全ての説明変量を使用した回帰式を作成し、それぞれの偏回帰係数のF値を求め、最小のF値でなおかつ2.0以下のものがあれば、その変量を削除する。
②①から1つ変量を減らした回帰式を作成し、それぞれの偏回帰式のF値を求め、最小のF値でなおかつ2.0以下のものがあれば、その変量を削除する。これを繰り返す。
または、寄与率R2を見ていき、その変量を削除しても余り寄与率の減少がみられないときには、その変量はなくてもよい変量なので削除する。
③変数減少の打ち切り
全ての変量について実行が終了し、もう削除すべき変量がなくなったとき。
または、あらかじめ決めた決定値(R2)に達したとき。
(3)変数増減法
変数増加法と似ているが、一度取り込んだ変数についても、その偏回帰係数のF値が2.0以下になるときには、回帰式から削除する。
(4)変数減増法
変数減少法に似ているが、一度削除した変数についても、再度取り込んでその偏回帰係数を調べその値が2.0以上になるときには再度取り込むようにする。
以上偏回帰係数を調べて変量の増加減少を行ってきたが、AIC量を見ながら変量の増減をしていく方法がある。
偏回帰係数のF値と同様に、AIC量を調べながら、①変数増加法 ②変数減少法 ③変数増減法 ④変数減増法 がある。
AIC量を見ながらこれらの方法を行うときには、採否の基準とする偏回帰係数のF値は、自由度に関係なく
F=(n-p-1)・(e2/n -1) を使用する。
n:標本数 p:説明変量の個数
1.11 残差εについて
回帰式において、残差εをみると
残差εについての仮定は
![]() ①εi・εj はお互いに独立で、正規分布N(0,σ2)に従う。
①εi・εj はお互いに独立で、正規分布N(0,σ2)に従う。
②εの期待値は0である。
③εの分散は一定である。
以上の仮定下で線形重回帰モデルは
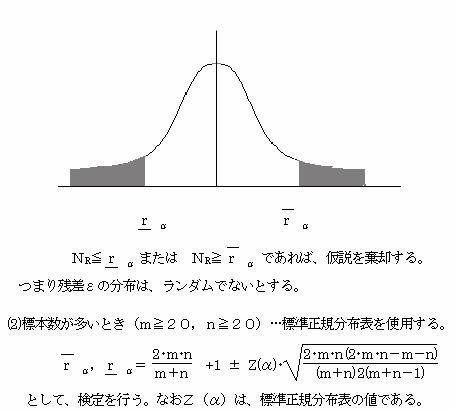
yi=β1・x1i+β2・x2i+…+βp・xpi+β0+εi (i=1,2 …n)とするとき残差εの分布は、ランダムでありかつ正規分布にしたがう。
いま、データが系時的に変化するとき、残差εは系時的に変化する。この残差の系時的変化を見ることにより、残差εのランダム性を調べることができる。
残差εのランダム性を調べるには、下の2つの方法がある。
①残差の系時的プロット図を作成し、その図から読み取る方法
②ダービン・ワトソン比を求め調べる方法
1.11.1 残差プロットを見る方法
データが系時的に変化しているとき、その回帰式を求め、回帰式からのずれであるεを時系列に表示する。
残差をみて、全体的傾向・+-の出現状況・連の長さと数等を調べ、ランダム性を検討する。
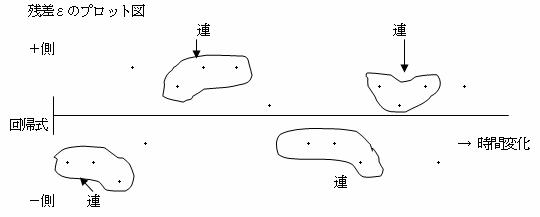
連…+データ・-データが連続して現れるとき、それを連という。
上のサンプルでの出現状況は、+側:-側=9:9=1:1となっている。
(1)残差εの分布が+側の分布と-側の分布が同様に分布しているかどうか調べるには、符号検定を行う。
|
標本 |
説明変量 x1 x2
… xp |
実測値 y |
予測値 Y |
残差 ε |
残差の符号 +・- |
|
1 2 … n |
x11 x21 … xp1 x12
x22 … xp2 … x1n
x2n … xpn |
y1 y2 … yn |
Y1 Y2 … Yn |
ε1 ε2 … εn |
|
残差εi=yi-Yiである。
「符号検定の実施」
残差εを求める。この時ε=0のものがn0個あれば、標本数をn-n0個とする。
検定統計量Sは+の符号の数とする。
(1)標本数が少ないとき(n≦30)…符号検定表を使用する
①仮説をたてる
仮 説 H0:μ1=μ2 (2つの分布は等しい)
対立仮説 H1:μ1≠μ2 (2つの分布は等しくない)
②検定統計量Sは
S=残差の符号が+の数
③有為水準=αで両側検定を行う(符号検定表より上限・下限を求める)
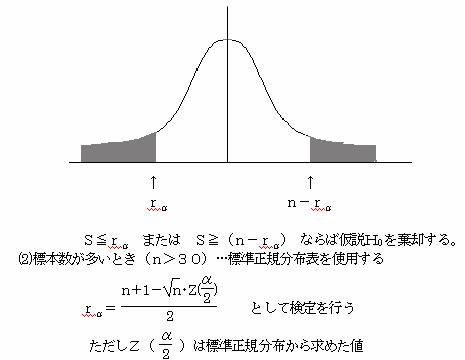
(2)残差εの分布が、ランダムに分布しているかの検定には、「連の数」による検定がある。
残差の「ある符号」の数をmとし、「反対の符号の数」をnとする。m+n=Nとする。
この時「+の連」、「-の連」を合わせた全体の「連の数」をNRとする。
NR=「+の連の個数」+「-の連の個数」
(1)標本数が少ないとき(m<20,n<20)…連の数の検定表使用する。
①仮説をたてる
仮 説 H0:残差εの分布はランダムである
対立仮説 H1:残差εの分布はランダムでない
②検定統計量NRは全体の連の数である
③有為水準αで検定を行う(連の数の検定表から上限・下限を求める)
1.11.2 ダービン・ワトソン比を用いる方法
残差の連なりがランダムであるかどうかを検定するには、ダービン・ワトソン比を用いる方法がある。ダービン・ワトソン比をdとすると
![]()
ダービン・ワトソン比とランダム性との関係は
①残差が全くランダムである時…d≒2
②残差に正の自己相関がある時…d→0に近づく
③残差に負の自己相関がある時…d→4に近づく
という性質を持っている。
自己相関とは、系時的残差変化間の相関をいう
残差εの自己相関を検定する
(1)正の自己相関があるか
(1)仮説
帰無仮説
H0:ρ=0 (自己相関はない)
対立仮説 H1:ρ>0
(正の自己相関がある)
(2)検定統計量はd比である。
(3)有為水準αで検定を行う
d<dLならば、仮説H0:ρ=0を棄却する。ρ>0を採択。
d>dUならば、仮説H1:ρ=0を採択する。
dU<d<dLならば、ρ=0 ρ>0のどちらともいえない。
(2)負の自己相関があるか
負の自己相関を検定するときには、dの代わりに4-dとして検定を行う。
(1)仮説
帰無仮説
H0:ρ=0 (自己相関はない)
対立仮説 H1:ρ<0
(負の自己相関がある)
(2)検定統計量はd比である。
(3)有為水準αで検定を行う
d>4-dLならば、仮説H0:ρ=0を棄却する。ρ<0を採択。
d<4-dUならば、仮説H1:ρ=0を採択する。
4-dU<d<4-dLならば、ρ=0 ρ>0のどちらともいえない。
(3)正・負どちらか不明の時
(1)仮説
帰無仮説
H0:ρ=0 (自己相関はない)
対立仮説 H1:ρ≠0 (自己相関はない)
(2)検定統計量はd比である。
(3)有為水準αで検定を行う
d≦dLまたはd>4-dLなら仮説ρ=0を棄却する。(ρ≠0を採択)
dU<d<4-dUなら仮説ρ=0を採択する。
その他は不明
2. 重回帰分析例題
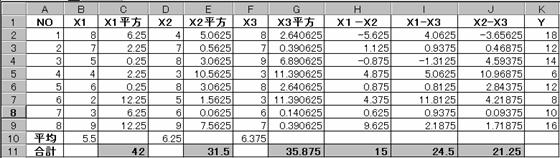
ある会社の8店舗について、その店舗ごとの店員の充実度(X1)・売り場面積(X2)・商品充実度(X3)を10点評価で調査し、またそれぞれの店の月平均売上高について調べて表にしたものが下の表である。
|
NO |
店員充実度 |
売り場面積 |
商品充実度 |
売上高(百万円) |
|
X1 |
X2 |
X3 |
Y |
|
|
1 2 3 4 5 6 7 8 |
8 7 5 4 6 2 3 9 |
4 7 8 3 8 5 6 9 |
8 7 9 3 8 3 6 7 |
18 12 14 6 12 8 10 16 |
以上の表をもとにして、X1~X3の3要素と売上高(Y)との間に何らかの関係があるかを重回帰分析を実行し調べる。
重回帰分析を実行するには、まず分析用のデータをシートに入力しておく。データを入力後、重回帰分析を実行する。
目的変量は売上高(Y)であり、説明変量はX1~X3の3変量である。
2.1 重回帰式を求める。
重回帰式を、Y=b1・x1+b2・x2+b3・x3+b0 とする。
2.1.1 偏差平方和・偏差積和を求める
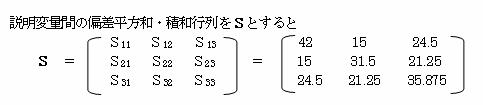
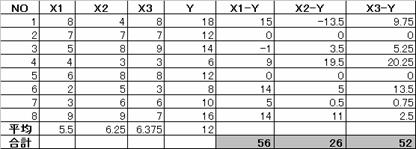
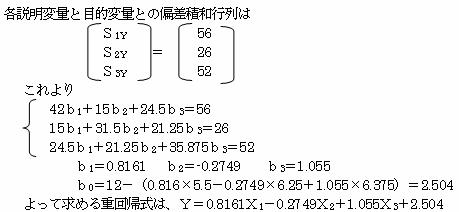
2.1.2 標準偏回帰係数を求める。
母集団に対する標準偏差を、関数 =STDEVP(範囲)で求める。
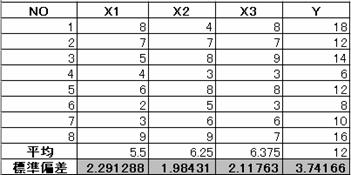
=STDEVP(範囲)で求めた標準偏差
![]()

標準偏回帰係数の値から、目的変量に与える影響は変量X3が最も大きく、次に変量X1である。
2. 1.3 予測値と残差を求める。
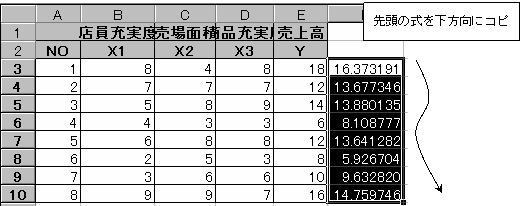
予測式は、Y=0.8161X1-0.2749X2+1.055X3+2.504
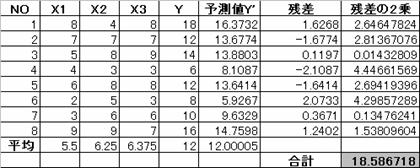
2.1.4 偏回帰係数の標準誤差(SE)を求める。
残差平方和(SE)は、SE=18.587 また不偏分散VE=18.587÷4=4.647
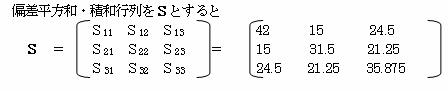
その逆行列S-1 を求める。
(1)=MINVERSE(範囲)関数で、先頭の値を求める。
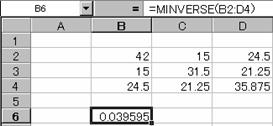
(2)求めた先頭の値を展開する。

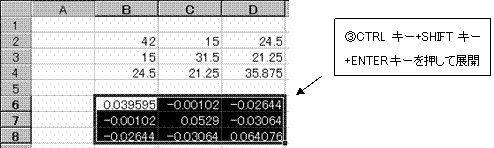

2.1.6 重相関係数の値を見ると非常に正の相関が高そうである。そこで母相関係数をρとして、無相関の検定を行う。
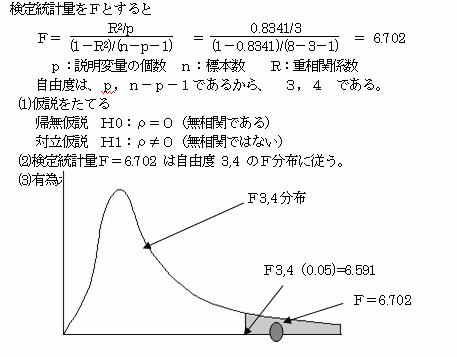
F=6.702>F3,4(0.05)=6.591 であり棄却域にはいる。よって帰無仮説H0:ρ=0を棄却する。母相関係数≠0であり、相関があるといえる。
2.7 自由度調整済重相関係数を求める。

2.8 求めた重回帰式の信頼性を検定する。
全変動(ST)=112
自由度:8-1=7
回帰による変動(SR)=93.4163 自由度:3
残差による変動(SE)=18.5867 自由度:8-3-1=4
以上から分散分析表を作成すると
|
|
平方和 |
自由度 |
不偏分散 |
分散比 |
|
回帰変動 |
93.4163 |
3 |
31.1388 |
F=6.701 |
|
残差変動 |
18.5867 |
4 |
4.6467 |
|
|
全変動 |
112 |
7 |
|
|
無相関の検定と同様の結果を得られる。求めた重回帰式は予測に役立つといえる。
2.8.1 偏回帰係数の信頼性を検定する
求めら重回帰式は信頼性があると検定で明らかになったので、次に重回帰式の偏回帰係数の有効性を検定する。偏回帰係数biを検定する。
検定統計量をFとすると
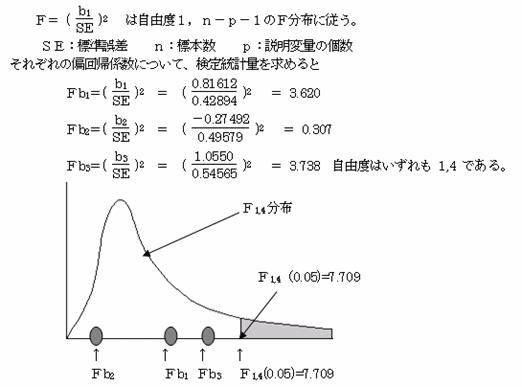
いずれも棄却域に入いらない。帰無仮説(母偏回帰係数β1・β2・β3=0)を棄却できない。
重回帰式は信頼性があるが、それぞれの偏回帰係数の有効性があるといえない。
2.8.2 偏相関係数を求める
偏相関係数は、説明変量Xiと目的変量との相関係数であり、他の説明変量の影響を取り除いたものである。どの説明変量が、目的変量と一番関係が深いかを知ることができる。
説明変量Xiと目的変量との偏相関係数を求める。
単相関係数行列をRとすると
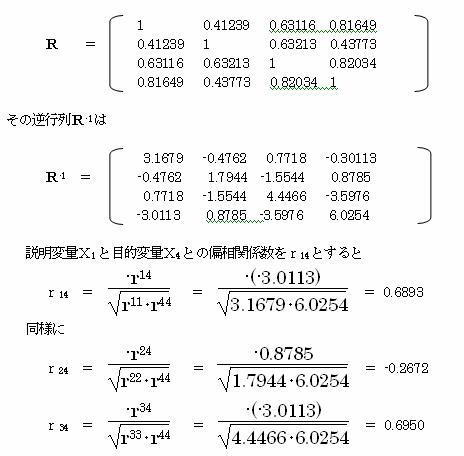
偏相関係数を見ると、r34=0.6950 であり、変量X3 と目的変量の関係が一番深いことが分かる。
2.9 回帰分析ツールの使用
2.9.1 Excelには、分析用ツールとして回帰分析ツールが備わっている。この回帰分析ツールを使用すえると、分析したいデータの入力されている範囲を指定するだけで、回帰分析を実施してくれる。
(1)データ入力後 → ツール → 分析ツール → 回帰分析をクリックして選択
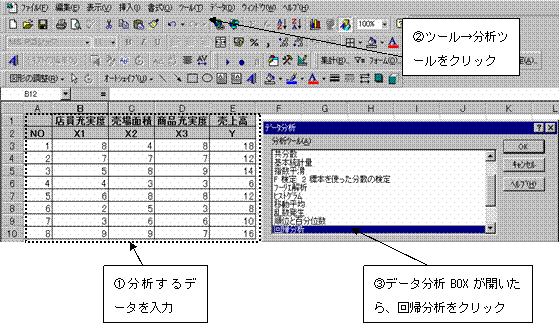
(2)分析するデータの範囲を指定
入力Yは目的変量のデータ範囲を指定(常に1列データ範囲)、入力Xは説明変量範囲(連続した列の範囲)先頭行をラベルとして使用する時は、ラベルの項目をクリック。分析結果を表示する位置を指定する。また何の分析を実施するかをクリックしてチェックする。すべての指定が終了したら、OKボタンをクリック。
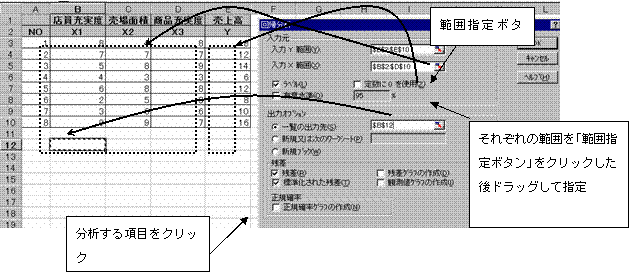
(3)一覧の出力先として指定したセル(B12)以降に分析結果が表示される。
|
概要 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
回帰統計 |
|
|
|
|
|
|
|
|
|
重相関 R |
0.91326 |
|
|
|
|
|
|
|
|
重決定 R2 |
0.83405 |
|
|
|
|
|
|
|
|
補正 R2 |
0.70958 |
|
|
|
|
|
|
|
|
標準誤差 |
2.15562 |
|
|
|
|
|
|
|
|
観測数 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
分散分析表 |
|
|
|
|
|
|
|
|
|
|
自由度 |
変動 |
分散 |
観測された分散比 |
有意 F |
|
|
|
|
回帰 |
3 |
93.413 |
31.138 |
6.701077754 |
0.04869 |
|
|
|
|
残差 |
4 |
18.587 |
4.6467 |
|
|
|
|
|
|
合計 |
7 |
112 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
係数 |
標準誤差 |
t |
P-値 |
下限 95% |
上限 95% |
下限 95.0% |
上限 95.0% |
|
切片 |
2.50414 |
2.7503 |
0.9105 |
0.41406029 |
-5.1319 |
10.1401 |
-5.1319 |
10.1401 |
|
X1 |
0.81612 |
0.4289 |
1.9027 |
0.129839733 |
-0.3748 |
2.00704 |
-0.3748 |
2.00704 |
|
X2 |
-0.2749 |
0.4958 |
-0.555 |
0.6087767 |
-1.6515 |
1.10163 |
-1.6515 |
1.10163 |
|
X3 |
1.05497 |
0.5457 |
1.9334 |
0.125323541 |
-0.46 |
2.56996 |
-0.46 |
2.56996 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
残差出力 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
観測値 |
予測値: Y |
残差 |
標準残差 |
|
|
|
|
|
|
1 |
16.3732 |
1.6268 |
0.9984 |
|
|
|
|
|
|
2 |
13.6773 |
-1.677 |
-1.029 |
|
|
|
|
|
|
3 |
13.8801 |
0.1199 |
0.0736 |
|
|
|
|
|
|
4 |
8.10878 |
-2.109 |
-1.294 |
|
|
|
|
|
|
5 |
13.6413 |
-1.641 |
-1.007 |
|
|
|
|
|
|
6 |
5.9267 |
2.0733 |
1.2724 |
|
|
|
|
|
|
7 |
9.63282 |
0.3672 |
0.2253 |
|
|
|
|
|
|
8 |
14.7597 |
1.2403 |
0.7611 |
|
|
|
|
|
上記分析結果から重回帰分析の結果を検討するようにする。
2.9.2 標準偏回帰係数を求める
分析するデータを標準化して、その標準化されたデータについて回帰分析を実施すると、標準偏回帰係数を求めることができる。
(1)分析するデータを標準化する。
データを標準化するには、(X - )/δ δ:標準偏差 で各データを標準化する。
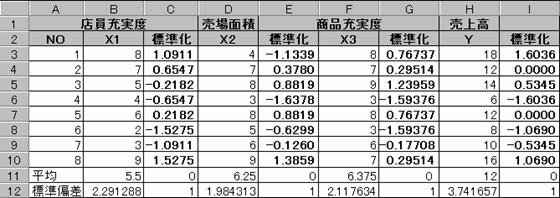
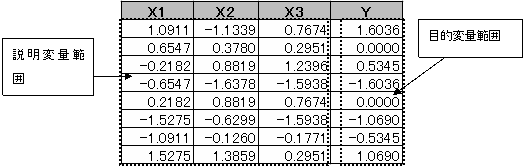
(2)標準化されたデータのみ、値複写で新しい表を作成する。
元の表で標準化されたデータを、形式指定複写の値複写で標準化データのみの新しい表を作成する。
(3)標準化されたデータの表を使用して、回帰分析を実施
|
概要 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
重相関 R |
0.91326 |
|
|
|
|
|
|
|
|
重決定 R2 |
0.83405 |
|
|
|
|
|
|
|
|
補正 R2 |
0.70958 |
|
|
|
|
|
|
|
|
標準誤差 |
0.57611 |
|
|
|
|
|
|
|
|
観測数 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
分散分析表 |
|
|
|
|
|
|
|
|
|
|
自由度 |
|
分散 |
観測された分散比 |
有意 F |
|
|
|
|
回帰 |
3 |
6.672377 |
2.224126 |
6.701078 |
0.048686 |
|
|
|
|
残差 |
4 |
1.327623 |
0.331906 |
|
|
|
|
|
|
合計 |
7 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
係数 |
標準誤差 |
t |
P-値 |
下限 95% |
上限 95% |
下限 95.0% |
上限 95.0% |
|
切片 |
2.7E-18 |
0.203687 |
1.33E-17 |
1 |
-0.56553 |
0.565526 |
-0.56553 |
0.565526 |
|
X 値 1 |
0.49977 |
0.262668 |
1.902661 |
0.12984 |
-0.22952 |
1.229053 |
-0.22952 |
1.229053 |
|
X 値 2 |
-0.1458 |
0.262934 |
-0.5545 |
0.608777 |
-0.87582 |
0.584226 |
-0.87582 |
0.584226 |
|
X 値 3 |
0.59707 |
0.30882 |
1.933406 |
0.125324 |
-0.26035 |
1.454496 |
-0.26035 |
1.454496 |


標準化されたデータを使用して、回帰分析を実施すると標準偏回帰係数が求められる。この係数を使用すると、目的変量の値も求めることができる。標準偏回帰係数を見ると、X3の係数が最も大きく、目的変量に与える影響が一番大きい係数であることが分かる。もっとも元のデータにおいて、説明変量間の単位が同じであるから、標準偏回帰係数を求めなくても通常の偏回帰係数を見るだけで、どの説明変量が目的変量に与える影響が一番大きいかが分かる。
|
残差出力 |
|
|
|
||
|
|
|
|
|
||
|
標準偏回帰係数を使用した、予測値が求められる |
予測値: Y |
残差 |
標準残差 |
||
|
1 |
1.16878 |
0.434783 |
0.998353 |
||
|
|
0.44829 |
-0.44829 |
-1.02937 |
||
|
3 |
0.50249 |
0.032035 |
0.073559 |
||
|
4 |
-1.04 |
-0.56359 |
-1.29413 |
||
|
5 |
0.43865 |
-0.43865 |
-1.00723 |
||
|
6 |
-1.6232 |
0.554112 |
1.272357 |
||
|
7 |
-0.6327 |
0.098133 |
0.225334 |
||
|
8 |
0.73757 |
0.331472 |
0.761129 |
標準偏回帰係数を使用した予測式は、 Y
= 0.49977 X1 - 0.1458X2 + 0.59707X3 である。
この予測式を用いて予測値が計算されて求められる。
(4) 求められた予測値を更に標準化する。
|
NO |
X1 |
X2 |
X3 |
Y |
予測値: Y |
標準化 |
|
1 |
1.0911 |
-1.1339 |
0.7674 |
1.6036 |
1.168784 |
1.27979 |
|
2 |
0.6547 |
0.3780 |
0.2951 |
0.0000 |
0.448290 |
0.49087 |
|
3 |
-0.2182 |
0.8819 |
1.2396 |
0.5345 |
0.502487 |
0.55021 |
|
4 |
-0.6547 |
-1.6378 |
-1.5938 |
-1.6036 |
-1.039973 |
-1.13875 |
|
5 |
0.2182 |
0.8819 |
0.7674 |
0.0000 |
0.438651 |
0.48031 |
|
6 |
-1.5275 |
-0.6299 |
-1.5938 |
-1.0690 |
-1.623157 |
-1.77732 |
|
7 |
-1.0911 |
-0.1260 |
-0.1771 |
-0.5345 |
-0.632656 |
-0.69274 |
|
8 |
1.5275 |
1.3859 |
0.2951 |
1.0690 |
0.737573 |
0.80762 |
|
平均 |
0.0000 |
0.0000 |
0.0000 |
0.0000 |
0.0000 |
0.00000 |
|
標準偏差 |
1 |
1 |
1 |
1 |
0.9132618 |
1.00000 |
2.9.3 重回帰分析に関する関数を使用して、重回帰分析を実施
(1)各変量の係数とY切片および重回帰式の検定を実施する関数:==LINEST関数
=LINEST関数:==LINEST(既知目的変量Yの範囲、既知説明変量Xの範囲,,TRUE)
①=LINEST関数で、説明変量の商品充実度(X3変量)の係数を求める。
関数を使用するセル位置をクリックした後、関数のアイコンをクリックし、LINEST関数をクリック指定する。
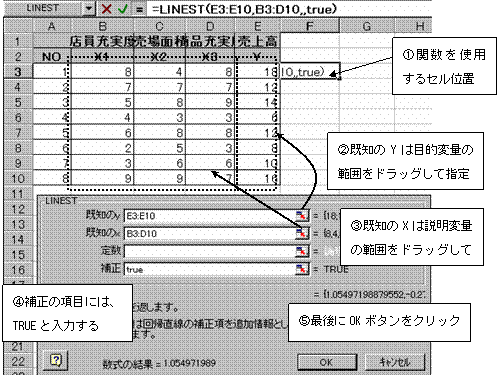
②先頭のX3の係数が求まったら、配列式を作成
現在分析に使用する説明変量は3つ、よって係数は説明変量分の3つとY切片の計4つの係数が必要であるから、配列指定は先頭のセルから横方向に4列分、また縦方向には常に5行分の範囲が必要である。よって先頭セルから横方向に4列・縦方向に5行分の範囲をドラッグして指定する。次に数式バーをクリックしアクティブにした後、CTRLキー+SHIFTキー+ENTERキーを押して配列式を完成する
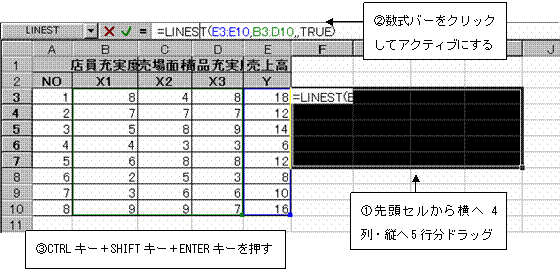
配列式が表示される
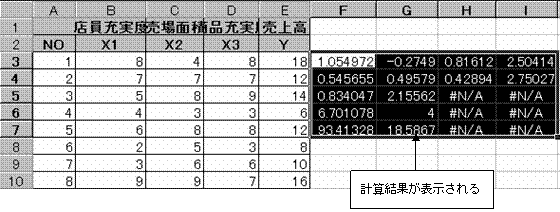
配列式に表示されているデータの意味
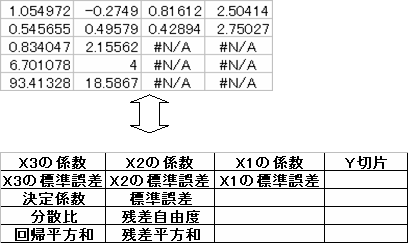
これより、重回帰式は Y=0.81612X1-0.2749X2+1.054972X3+2.50414 である。
またこの重回帰式の信頼性は、分散比(F値)=6.701078 であり、この値を使用して確率を求める関数で =FDIST(6.701078,3,4)=0.048686297 となり、求めた重回帰式は予測に役立たないという帰無仮説が棄却される。
(2)予測値を求める関数:=TREND関数
TREND関数を使用すると、重回帰式を使用して予測値を求めることができる。
TREND関数:=TREND(既知目的変量Y範囲,既知説明変量X範囲,新しいX範囲)である。
①既知目的変量Yの範囲および既知説明変量Xの範囲はドラッグして範囲指定後、F4キーを押して絶対座標にする。また新しいX範囲は、予測値を求めたいX1・X2・X3の範囲をドラッグして指定する。こちらは相対座標のままでよい。このようにして式を作成すれば、下方向にコピーして一度に予測値を求めることができる。
関数を使用するセル位置をクリックした後、関数のアイコンをクリックし、TREND関数をクリック指定する。
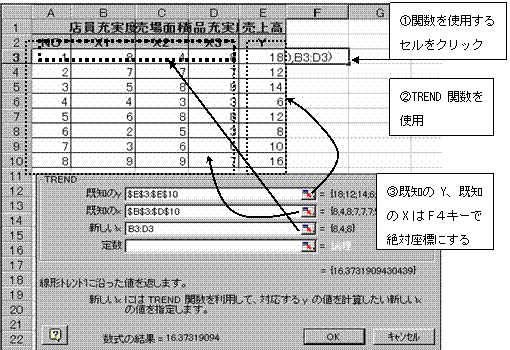
②先頭の式が作成できたら、下方向にコピーして他の予測値を求める。